Diseño en Bloques Completos al Azar (DBCA) y Análisis de Varianza
2025-09-12
Diseño en Bloques Completos al Azar (DBCA)
Objetivos de aprendizaje
Al finalizar este capítulo, el estudiante estará en capacidad de:
- Aplicar el diseño en bloques completos al azar (DBCA) en experimentos con una fuente de variabilidad conocida, comprendiendo la importancia del bloqueo para reducir el error experimental.
- Formular y evaluar la validez del modelo estadístico, incluyendo los efectos del factor de tratamiento y el factor de bloqueo.
- Interpretar el análisis de varianza (ANOVA) y las pruebas post-hoc para identificar diferencias significativas entre tratamientos, tanto de forma manual como con software estadístico.
Diseño en Bloques Completos al Azar (DBCA)
Introducción y definición
El Diseño en Bloques Completos al Azar (DBCA) es una extensión del Diseño Completamente al Azar (DCA), que se utiliza cuando existe una fuente de variabilidad conocida y controlable que no es de interés para la hipótesis principal, pero que podría enmascarar los efectos del tratamiento. Para mitigar esta variabilidad, las unidades experimentales se agrupan en bloques homogéneos. Dentro de cada bloque, los tratamientos se asignan completamente al azar. La idea es que la variabilidad dentro de un bloque sea mínima, mientras que la variabilidad entre bloques puede ser grande.
Características y situaciones de uso
- Homogeneidad dentro del bloque: Las unidades experimentales dentro de un bloque deben ser lo más parecidas posible.
- Heterogeneidad entre bloques: Los bloques pueden ser muy diferentes entre sí.
- Aleatorización: Los tratamientos se asignan al azar dentro de cada bloque, no en todo el experimento.
- Completos: Cada bloque debe contener todos los tratamientos.
- Adecuado para: Experimentos donde existen gradientes espaciales o temporales (p. ej., variaciones en la humedad del suelo, temperatura, diferencias entre días, turnos de trabajo o lotes de producción).
¿Cuándo no usar un DBCA?
Un DBCA no es la mejor opción cuando: - No hay una fuente de variabilidad previsible que necesite ser controlada. En este caso, un DCA es más simple y eficiente. - El número de tratamientos es muy grande, lo que hace que los bloques también sean muy grandes y, por ende, difíciles de mantener homogéneos. - Las unidades experimentales dentro de los bloques no son homogéneas, lo que invalida el propósito del diseño.
Ejemplo
Considera un experimento para evaluar el efecto de cuatro tipos de fertilizantes (tratamientos) en el crecimiento de plantas en un invernadero. El invernadero tiene un gradiente de temperatura y luz desde la ventana hasta la pared trasera. Este gradiente es una fuente de variabilidad que puede afectar el crecimiento de las plantas, independientemente del fertilizante. Para controlarla, se dividen las plantas en bloques (p. ej., por filas paralelas a la ventana), de modo que cada bloque abarca una zona con condiciones de luz y temperatura similares. Dentro de cada fila, se asignan los cuatro fertilizantes al azar.
¿Qué usar en su lugar?
Si existen dos o más fuentes de variabilidad que deben controlarse, se podrían usar otros diseños más complejos, como el Diseño de Cuadrado Latino (para dos factores de bloqueo) o diseños con factores anidados.
Hipótesis en un DBCA
- Hipótesis nula (H₀): Las medias de los tratamientos son iguales. \(H_0: \mu_1 = \mu_2 = \cdots = \mu_k\)
- Hipótesis alternativa (Hₐ): Al menos una media difiere. \(H_a: \exists \, i,j \; \mu_i \neq \mu_j\)
¿Se plantean hipótesis sobre los bloques?
Warning
Sólo se plantean hipótesis para los tratamientos. Los bloques no son de interés inferencial → no se comparan entre sí.
Un bloque es una fuente de variabilidad no controlada (espacio, tiempo, día, parcela, lote, módulo, etc.), que se busca neutralizar.
No son tratamientos experimentales, sino condiciones del entorno.
No se busca identificar el bloque “mejor”, sino neutralizar su efecto para que no interfiera en la comparación de tratamientos.
Modelo estadístico del DBCA
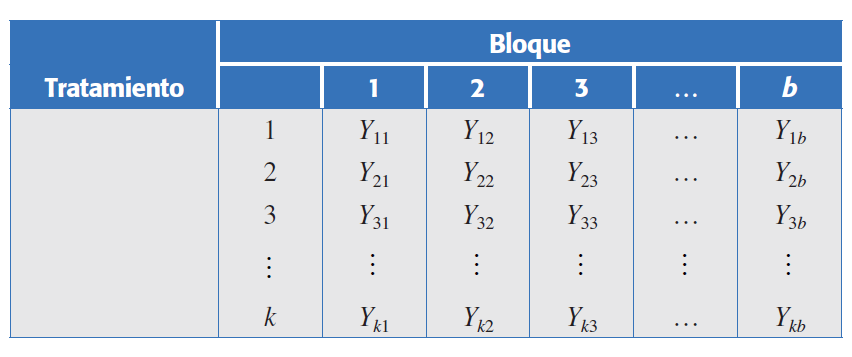
Modelo estadístico del DBCA
El modelo para un diseño en bloques completos al azar con un solo factor de tratamiento es:
\[Y_{ij} = \mu + \tau_i + \gamma_j + \varepsilon_{ij}; \quad \begin{cases} i = 1,2, \ldots, k \\ j = 1,2, \ldots, b \end{cases}\] ||
La fórmula anterior es un modelo lineal utilizado para el análisis de varianza (ANOVA). Cada uno de sus componentes representa un efecto específico sobre la variable de respuesta \(Y_{ij}\).
Donde :
\(Y_{ij}\): Es la variable de respuesta o la observación para el tratamiento \(i\) en el bloque \(j\).
\(\mu\): Es la media general o el efecto promedio de toda la población.
\(\tau_i\): Es el efecto del tratamiento \(i\). Representa la desviación de la media general causada por el tratamiento específico.
\(\gamma_j\): Es el efecto del bloque \(j\). Representa la desviación de la media general causada por el bloque en el que se encuentra la observación.
\(\varepsilon_{ij}\): Es el error aleatorio asociado a la observación \(Y_{ij}\). Este término captura toda la variabilidad no explicada por los efectos del tratamiento o del bloque. Se asume que estos errores son independientes y se distribuyen normalmente.
\(i = 1, 2, \ldots, k\): El subíndice \(i\) va desde 1 hasta \(k\), donde \(k\) es el número total de tratamientos.
\(j = 1, 2, \ldots, b\): El subíndice \(j\) va desde 1 hasta \(b\), donde \(b\) es el número total de bloques.
Este modelo es fundamental para entender cómo diferentes factores (tratamientos y bloques) influyen en una variable de interés en un diseño experimental.
Supuestos del modelo
Los supuestos del modelo son los mismos que para el DCA, aplicados a los residuos (\(\varepsilon_{ij}\)):
Normalidad: Los residuos deben seguir una distribución normal.
Homocedasticidad: La varianza de los residuos debe ser constante para todos los tratamientos y bloques.
Independencia: Los residuos deben ser independientes entre sí.
Del modelo al ANOVA y notación de puntos
El Análisis de Varianza (ANOVA) es la técnica estadística que se utiliza para probar las hipótesis del modelo. El objetivo es descomponer la variación total de los datos en componentes atribuibles a las fuentes de variación del modelo (tratamientos y bloques) y al error.
Descomposición de la variación total
La suma de cuadrados total (\(SCT\)) se descompone en tres partes: la suma de cuadrados de los tratamientos (\(SCTR\)), la de los bloques (\(SCB\)) y la del error (\(SCE\)).
\[\boxed{\,SCT = SCTR + SCB + SCE\,}\]
\[ SCT = \sum_{j=1}^{b}\sum_{i=1}^{k} Y_{ij}^2 - \frac{Y_{\cdot\cdot}^2}{N} \]
\[ SCTRAT = \sum_{i=1}^{k}\frac{Y_{i\cdot}^2}{b} - \frac{Y_{\cdot\cdot}^2}{N} \]
\[ SCB = \sum_{j=1}^{b}\frac{Y_{\cdot j}^2}{k} - \frac{Y_{\cdot\cdot}^2}{N} \]
\[ SCE = SCT - SCTRAT - SCB \]
SCTR: Representa la variabilidad de las medias de los tratamientos con respecto a la media global. Si esta SC es grande, indica que existe una diferencia entre los tratamientos.
SCB: Representa la variabilidad de las medias de los bloques con respecto a la media global. Si esta SC es grande, confirma que el bloqueo fue efectivo en controlar una fuente de variabilidad.
SCE: Representa la variabilidad residual o no explicada por los tratamientos y los bloques. Es la varianza experimental. El objetivo del DBCA es reducir este valor para hacer la prueba de los tratamientos más poderosa.
Grados de libertad (gl)
- Total: \(gl_T = N - 1\)
- Tratamientos: \(gl_{Tr} = k - 1\)
- Bloques: \(gl_B = b - 1\)
- Error: \(gl_E = (k - 1)(b - 1)\)
Cuadrados Medios (CM)
Los cuadrados medios se obtienen dividiendo cada suma de cuadrados por sus respectivos grados de libertad:
\[CM_{Tr}=\frac{SCTR}{k-1}, \quad CM_B=\frac{SCB}{b-1}, \quad CM_E=\frac{SCE}{(k-1)(b-1)}\]
Tabla ANOVA para DBCA
| Fuente | SC | gl | CM | F | p-valor |
|---|---|---|---|---|---|
| Tratamientos | \(SCTR\) | \(k-1\) | \(CM_{Tr}=\dfrac{SCTR}{k-1}\) | \(F_{Tr}=\dfrac{CM_{Tr}}{CM_E}\) | \(\Pr\{F_{k-1,\,(k-1)(b-1)}\ge F_{Tr}\}\) |
| Bloques | \(SCB\) | \(b-1\) | \(CM_{B}=\dfrac{SCB}{b-1}\) | \(F_{B}=\dfrac{CM_{B}}{CM_E}\) | \(\Pr\{F_{b-1,\,(k-1)(b-1)}\ge F_{B}\}\) |
| Error | \(SCE\) | \((k-1)(b-1)\) | \(CM_{E}=\dfrac{SCE}{(k-1)(b-1)}\) | — | — |
| Total | \(SCT\) | \(N-1\) | — | — | — |
La regla de decisión es rechazar la hipótesis nula si el valor de F calculado es mayor que el valor crítico de la tabla, o si el p-valor es menor que el nivel de significancia (\(\alpha\)).
| Situación | Interpretación |
|---|---|
| Bloques significativos | Existían diferencias entre bloques → el bloqueo fue necesario. |
| Bloques no significativos | El bloqueo no redujo mucho la variación, pero tampoco invalida el análisis. |
| Comparar bloques | ❌ Incorrecto: no buscamos el “mejor” o “peor” bloque. |
Eficiencia Relativa del DBCA
La Eficiencia Relativa (ER) es una medida que compara la precisión del Diseño en Bloques Completos al Azar (DBCA) con la de un Diseño Completamente al Azar (DCA) que se hubiera ejecutado con las mismas unidades experimentales. Su objetivo es determinar si la estrategia de bloqueo fue efectiva.
La fórmula de la eficiencia relativa es:
\[ER = \frac{(gl_B)CM_B + (gl_E)CM_E}{(gl_T)CM_E}\]
Interpretación:
Si ER > 1, el DBCA es más eficiente que el DCA. Esto significa que el bloqueo fue efectivo en reducir el error experimental, y la prueba de los tratamientos es más poderosa.
Si ER = 1, el DBCA es tan eficiente como el DCA.
Si ER < 1, el DBCA es menos eficiente que el DCA. El uso de bloques en realidad aumentó el error experimental, y el DCA hubiera sido una mejor opción.
Comparaciones múltiples
Una vez que el ANOVA muestra un efecto significativo de los tratamientos, es necesario realizar pruebas de comparaciones múltiples para identificar qué tratamientos específicos difieren entre sí. Las pruebas más comunes son: - Tukey HSD: La más utilizada para comparar todas las medias entre sí. - Dunnett: Para comparar cada tratamiento contra un control. - Bonferroni, Scheffé, LSD, Duncan: Otras pruebas con diferentes niveles de conservadurismo y potencia.
Resumen visual de pruebas
Un gráfico de medias con intervalos de confianza puede ayudar a visualizar las diferencias. Además, las pruebas post-hoc suelen agrupar los tratamientos en “grupos homogéneos” con letras.
Verificación de supuestos del modelo
Es crucial validar los supuestos del modelo para asegurar la validez de los resultados del ANOVA.
Normalidad: Se verifica con un gráfico de probabilidad normal (Q-Q plot) y pruebas estadísticas como Shapiro-Wilk.
Homocedasticidad: Se verifica con un gráfico de residuos vs. valores ajustados y pruebas como la de Bartlett o Levene.
Independencia: Se asume por el diseño experimental y la aleatorización adecuada.
Caso aplicado: DBCA en remediación de suelos con biochar
The Influence of Biochar on Heavy Metals Phytoaccumulation by Okra and Fluted Pumpkin Plants in Soil ContaminatedWith Petroleum Hydrocarbons Environmental Quality Management.

Contexto y objetivo
Sitio contaminado con aceite de motor usado (“mechanic village”, Uyo, Nigeria).
Objetivo: evaluar biochar como enmienda para reducir metales pesados (Cd, Cr, Pb, Ni) y el riesgo ecológico, usando plantas fitoacumuladoras (okra y fluted pumpkin).
Diseño experimental (DBCA)
- Tipo de diseño: Diseño en Bloques Completamente al Azar (DBCA) con arreglo factorial 3 × 3 (biochar × cultivo), utilizando 3 bloques (réplicas) para controlar la variabilidad espacial del terreno.
Diseño experimental (DBCA)
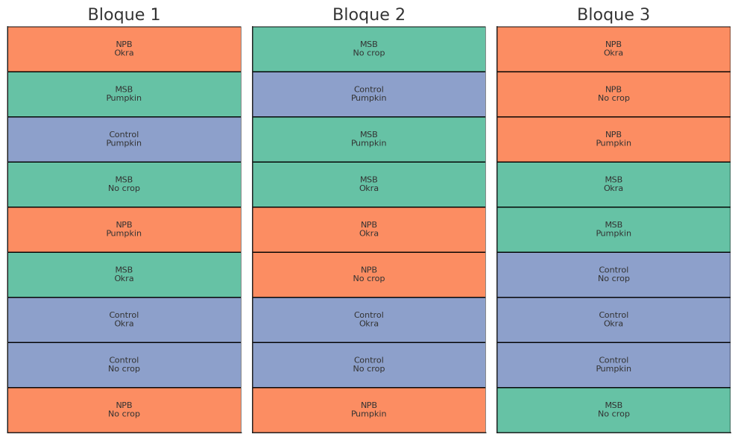
Cada bloque contiene las 9 combinaciones posibles de Biochar (MSB, NPB, Control) × Cultivo (okra, pumpkin, no crop).
🟩 MSB 🟧 NPB 🟦 Control
Factores
Factores principales (tratamientos):
- Biochar:
- MSB (maize stalk biochar)
- NPB (nipa palm biochar)
- Sin biochar (control)
- MSB (maize stalk biochar)
- Cultivo:
- Okra
- Fluted pumpkin
- Sin cultivo (control)
- Okra
- Biochar:
Factor de bloqueo: las tres repeticiones en diferentes secciones del terreno, empleadas para controlar la heterogeneidad espacial del lote experimental.
Número total de unidades experimentales: 3 (biochar) × 3 (cultivo) × 3 (bloques) = 27 parcelas.
- Parcela experimental total: 21.5 m × 8.5 m
- Tamaño de cada parcela: 1.5 m × 1.5 m
- Parcela experimental total: 21.5 m × 8.5 m
Aplicación de tratamientos:
- Dosis de biochar: 20 t ha⁻¹ incorporado a 0–20 cm de profundidad; reposo de 1 mes antes de la siembra.
- Siembra bajo lluvia:
- Okra: aclareo a 2 plantas/parcela.
- Fluted pumpkin: aclareo a 1 planta/parcela.
- En las parcelas sin cultivo no se establecieron plantas (control).
- Okra: aclareo a 2 plantas/parcela.
- Dosis de biochar: 20 t ha⁻¹ incorporado a 0–20 cm de profundidad; reposo de 1 mes antes de la siembra.
Variables medidas
Suelo (0–30 cm): textura, densidad aparente (BD), humedad (%MC), conductividad hidráulica saturada (Ks), hidrocarburos totales de petróleo (TPH) y metales (Cd, Cr, Pb, Ni, mediante AAS Buck VGP 210).
Plantas: concentración de Cd, Cr, Pb, Ni en brotes; Factor de Bioacumulación (BAF).
Riesgo ecológico (suelo): Hazard Quotient (HQ) con valores de referencia (TRV) por metal.
Fórmulas clave (evaluación ambiental)
- HQ (riesgo ecológico):
\[ HQ = \frac{MCT}{TRV} \]
Donde MCT = concentración medida en suelo; TRV = valor toxicológico de referencia.- Criterio: HQ > 1 indica riesgo elevado.
- BAF (bioacumulación en planta):
\[ BAF = \frac{C_{\text{planta}}}{C_{\text{suelo}}} \]
Nota sobre el análisis estadístico
- Se aplicó ANOVA de bloques completos al azar, considerando como factores principales el tipo de biochar y el tipo de cultivo, y como bloque las tres repeticiones en el terreno.
- Se realizaron comparaciones múltiples de medias según cada variable de respuesta (LSD).
Ejemplo práctico simulado
En una zona contaminada con hidrocarburos (TPH) se evalúan tres enmiendas biorremediadoras (A = biochar maíz; B = biochar palma; C = compost) sobre la reducción porcentual de TPH.
Se diseñó un DBCA con \(b=4\) bloques (lotes) y \(k=3\) tratamientos; una observación por celda (\(N=12\)).
- Factor principal (tratamiento): niveles \(A,B,C\).
- Factor de bloqueo: 4 bloques .
- Variable respuesta: \(y=\) reducción porcentual de TPH.
Datos
Los datos son:
| Tratamiento / Bloque | Bloque 1 | Bloque 2 | Bloque 3 | Bloque 4 | Total por tratamiento |
|---|---|---|---|---|---|
| A | 26.99 | 27.05 | 28.66 | 25.59 | \(Y_{A\cdot}=108.29\) |
| B | 23.72 | 21.53 | 25.03 | 21.57 | \(Y_{B\cdot}=91.85\) |
| C | 22.30 | 18.53 | 19.56 | 18.57 | \(Y_{C\cdot}=78.96\) |
| Total por bloque | \(Y_{\cdot1}=73.01\) | \(Y_{\cdot2}=67.11\) | \(Y_{\cdot3}=73.25\) | \(Y_{\cdot4}=65.73\) | \(Y_{\cdot\cdot}=279.10\) |
Hipótesis
Tratamientos: \[ H_0:\ \mu_A=\mu_B=\mu_C \qquad H_1:\ \exists\ i\neq j\ \text{con}\ \mu_i\neq\mu_j \]
#Cálculos manuales (paso a paso){.smaller}
Números básicos
\(N = 12\), \(k=3\), \(b=4\).
Total global: \(Y_{\cdot\cdot}=279.10\).
Media general: \[ \bar Y_{\cdot\cdot}=\frac{Y_{\cdot\cdot}}{N}=\frac{279.10}{12}=23.2583 \]
Totales por tratamiento (ya mostrados):
\(Y_{A\cdot}=108.29,\ Y_{B\cdot}=91.85,\ Y_{C\cdot}=78.96\).Totales por bloque:
\(Y_{\cdot1}=73.01,\ Y_{\cdot2}=67.11,\ Y_{\cdot3}=73.25,\ Y_{\cdot4}=65.73\).
Sumas de cuadrados
Suma de cuadrados total (SCT)
Usamos la forma computacional: \[ SCT = \sum_{i=1}^k\sum_{j=1}^b y_{ij}^2 - \frac{Y_{\cdot\cdot}^2}{N}. \]
Cálculo numérico (se muestran los valores intermedios): - \(\sum y_{ij}^2 = \; \sum \text{(cada }y^2\text{)} = (26.99^2+27.05^2+\dots+18.57^2) = 1358.8199666666673\) (suma de cuadrados individuales). - \(\dfrac{Y_{\cdot\cdot}^2}{N} = \dfrac{(279.10)^2}{12} = 1227.7800\).
Por tanto: \[ SCT = 1358.8199666666673 - 1227.7800 = 131.03996666666717. \]
(Redondeado según precisión en los siguientes pasos.)
Suma de cuadrados por tratamientos (SCTr)
Fórmula: \[ SCTr = \frac{\sum_{i=1}^k Y_{i\cdot}^2}{b} - \frac{Y_{\cdot\cdot}^2}{N}. \]
Cálculo: - \(\dfrac{\sum Y_{i\cdot}^2}{b} = \dfrac{108.29^2 + 91.85^2 + 78.96^2}{4} = 1335.836216666667\). - \(\dfrac{Y_{\cdot\cdot}^2}{N}=1227.7800\) (como arriba).
Entonces: \[ SCTr = 1335.836216666667 - 1227.7800 = 108.05621666666684. \]
Suma de cuadrados por bloques (SCB)
Fórmula: \[ SCB = \frac{\sum_{j=1}^b Y_{\cdot j}^2}{k} - \frac{Y_{\cdot\cdot}^2}{N}. \]
Cálculo: - \(\dfrac{\sum Y_{\cdot j}^2}{k} = \dfrac{73.01^2 + 67.11^2 + 73.25^2 + 65.73^2}{3} = 1243.1150333333338\). - \(\dfrac{Y_{\cdot\cdot}^2}{N}=1227.7800\).
Entonces: \[ SCB = 1243.1150333333338 - 1227.7800 = 15.33503333333374. \]
Suma de cuadrados del error (SCE)
Usamos: \[ SCE = SCT - SCTr - SCB. \]
Sustituyendo: \[ SCE = 131.03996666666717 - 108.05621666666684 - 15.33503333333374 = 7.648716666666587. \]
Grados de libertad y cuadrados medios
- \(df_{Tr}=k-1=2\).
- \(df_B=b-1=3\).
- \(df_E=(k-1)(b-1)=6\).
- \(df_T=Nb-1=11\) (ó \(N-1=11\)).
Cuadrados medios: \[ MS_{Tr}=\frac{SCTr}{df_{Tr}}=\frac{108.0562167}{2}=54.0281083, \] \[ MS_B=\frac{SCB}{df_B}=\frac{15.3350333}{3}=5.1116778, \] \[ MS_E=\frac{SCE}{df_E}=\frac{7.6487167}{6}=1.2747861. \]
Estadísticos \(F\)
\[ F_{Tr}=\frac{MS_{Tr}}{MS_E}=\frac{54.0281083}{1.2747861}=42.3820968. \]
\[ F_{B}=\frac{MS_{B}}{MS_E}=\frac{5.1116778}{1.2747861}=4.0098317. \]
Estos \(F\) se comparan con la distribución \(F\) con grados de libertad \((2,6)\) para tratamientos y \((3,6)\) para bloques para obtener p-valores.
Tabla ANOVA (resumen)
| Fuente | SC | gl | CM (MS) | \(F\) |
|---|---|---|---|---|
| Tratamientos | 108.0562 | 2 | 54.0281 | 42.3821 |
| Bloques | 15.3350 | 3 | 5.1117 | 4.0098 |
| Error | 7.6487 | 6 | 1.2748 | — |
| Total | 131.04 | 11 | — | — |
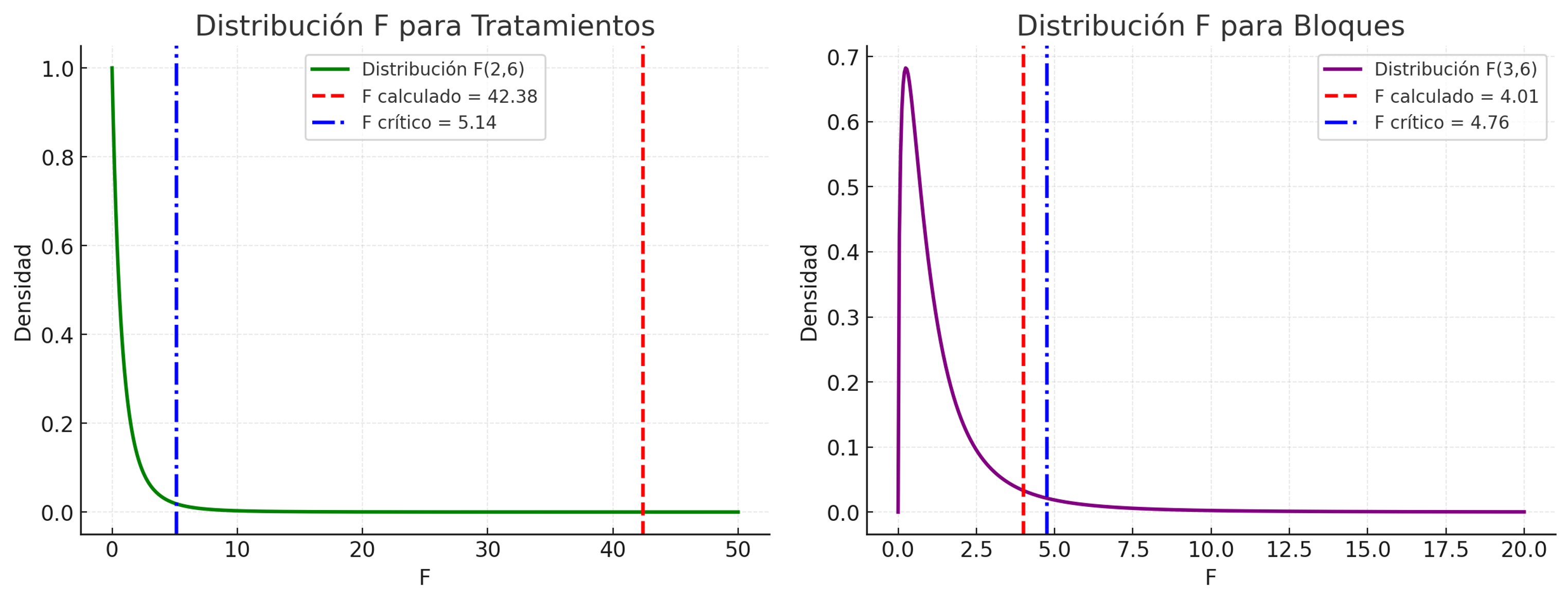 Los resultados del análisis de varianza permiten rechazar la hipótesis nula de igualdad de medias entre tratamientos, evidenciando diferencias estadísticamente significativas en la reducción porcentual de TPH. Sin embargo, esta conclusión debe interpretarse con cautela, ya que está supeditada al cumplimiento de los supuestos del modelo: normalidad de los residuos, homogeneidad de varianzas e independencia de las observaciones.
Los resultados del análisis de varianza permiten rechazar la hipótesis nula de igualdad de medias entre tratamientos, evidenciando diferencias estadísticamente significativas en la reducción porcentual de TPH. Sin embargo, esta conclusión debe interpretarse con cautela, ya que está supeditada al cumplimiento de los supuestos del modelo: normalidad de los residuos, homogeneidad de varianzas e independencia de las observaciones.
Eficiencia relativa (RCBD vs CRD)
Si se ignoraran los bloques (DCA/CRD), el error sería: \[ SCE_{CRD} = SCT - SCTr = 131.0399667 - 108.0562167 = 22.98375. \]
Grados de libertad error en CRD: \(df_{E,CRD} = N - k = 12 - 3 = 9.\)
Entonces: \[ MS_{E,CRD} = \frac{SCE_{CRD}}{df_{E,CRD}} = \frac{22.98375}{9} = 2.55375. \]
Recordando \(MS_{E,RCBD}=MS_E = 1.2747861\), la eficiencia relativa (ER) se define como: \[ ER = \frac{MS_{E,CRD}}{MS_{E,RCBD}} = \frac{2.55375}{1.2747861} = 2.0033. \]
Interpretación: el DBCA (con bloques) es \(\approx 2.00\) veces más eficiente que el CRD — es decir, el error residual se reduce a la mitad al introducir el bloqueo, justificando su uso.
Verificación de supuestos
Cálculo de residuos
Recordemos la estimación de cada celda en un DBCA: \[ \hat y_{ij} = \bar y_{i\cdot} + \bar y_{\cdot j} - \bar y_{\cdot\cdot}. \]
Las medias por tratamiento (promedios sobre bloques) son: - \(\bar y_{A\cdot}=27.0725\), \(\bar y_{B\cdot}=22.9625\), \(\bar y_{C\cdot}=19.7400\).
Las medias por bloque (promedios sobre tratamientos) son: - \(\bar y_{\cdot1}=24.3367\), \(\bar y_{\cdot2}=22.3700\), \(\bar y_{\cdot3}=24.4167\), \(\bar y_{\cdot4}=21.9100\).
Ahora calculamos \(\hat y_{ij}\) y los residuos \(e_{ij}=y_{ij}-\hat y_{ij}\). Se muestran las 12 filas:
| Obs | Trat. | Bloque | \(y_{ij}\) | \(\hat y_{ij}\) | Residual \(e_{ij}\) |
|---|---|---|---|---|---|
| 1 | A | 1 | 26.99 | 28.1508 | -1.1608 |
| 2 | A | 2 | 27.05 | 26.1842 | 0.8658 |
| 3 | A | 3 | 28.66 | 28.2308 | 0.4292 |
| 4 | A | 4 | 25.59 | 25.7242 | -0.1342 |
| 5 | B | 1 | 23.72 | 24.0408 | -0.3208 |
| 6 | B | 2 | 21.53 | 22.0742 | -0.5442 |
| 7 | B | 3 | 25.03 | 24.1208 | 0.9092 |
| 8 | B | 4 | 21.57 | 21.6142 | -0.0442 |
| 9 | C | 1 | 22.30 | 20.8183 | 1.4817 |
| 10 | C | 2 | 18.53 | 18.8517 | -0.3217 |
| 11 | C | 3 | 19.56 | 20.8983 | -1.3383 |
| 12 | C | 4 | 18.57 | 18.3917 | 0.1783 |
Verificación numérica: - \(\sum e_{ij} \approx 0\) (debe cumplirse por construcción). - \(\sum e_{ij}^2 = 7.6487 \approx SCE\) (coincide).
Normalidad
Aplicando la prueba de Shapiro–Wilk sobre los residuos: - Estadístico \(W = 0.9751\), \(p\)-valor \(= 0.9566\).
Interpretación: con \(\alpha=0.05\) no se rechaza la normalidad de los residuos.
Homogeneidad de varianzas
La prueba de Bartlett contrast a la hipótesis de igualdad de varianzas entre \(k\) grupos bajo la suposición de normalidad.
Sea \(s_i^2\) la varianza muestral del grupo \(i\) y \(n_i\) su tamaño (aquí \(n_i=4\) para cada tratamiento). Definimos:
- \(N = \sum_{i=1}^k n_i\) (tamaño total),
- \(S_p^2 = \dfrac{\sum_{i=1}^k (n_i-1)s_i^2}{N-k}\) (varianza combinada agrupada).
El estadístico corregido de Bartlett es \[ \chi_B^2 = \frac{(N-k)\ln S_p^2 - \sum_{i=1}^k (n_i-1)\ln s_i^2} {1 + \dfrac{1}{3(k-1)}\left(\displaystyle\sum_{i=1}^k \frac{1}{n_i-1} - \frac{1}{N-k}\right)}. \]
Bajo \(H_0\) (varianzas iguales) \(\chi_B^2 \sim \chi^2_{k-1}\) aproximadamente.
Datos por grupo (recuadro)
- Para A:
- \(\bar y_A = 27.0725\)
- \(s_A^2 = 1.5750916667\)
- Para B:
- \(\bar y_B = 22.9625\)
- \(s_B^2 = 2.9464916667\)
- Para C:
- \(\bar y_C = 19.7400\)
- \(s_C^2 = 3.1396666667\)
Varianza combinada (agrupada) \(S_p^2\)
Primero la suma ponderada: \[ \sum_{i=1}^k (n_i-1)s_i^2 = 3\cdot s_A^2 + 3\cdot s_B^2 + 3\cdot s_C^2 = 22.98375. \]
Luego: \[ S_p^2 = \frac{22.98375}{N-k} = \frac{22.98375}{12-3} = \frac{22.98375}{9} = 2.55375. \]
Numerador del estadístico (logaritmos)
Calculemos las dos piezas:
\((N-k)\ln S_p^2 = 9 \cdot \ln(2.55375) = 9 \cdot 0.937562867 = 8.4380658.\)
\(\sum_{i=1}^k (n_i-1)\ln s_i^2 = 3\ln(1.5750916667) + 3\ln(2.9464916667) + 3\ln(3.1396666667)= 8.0371359.\)
Diferencia: \[ L = (N-k)\ln S_p^2 - \sum_{i}(n_i-1)\ln s_i^2 = 8.4380658 - 8.0371359 = 0.4009299. \]
Factor de corrección \(C\)
La corrección de Bartlett es: \[ C = 1 + \frac{1}{3(k-1)}\left(\sum_{i=1}^k\frac{1}{n_i-1} - \frac{1}{N-k}\right). \]
Sustituyendo (\(k=3\), \(n_i-1=3\) para cada grupo): - \(\sum 1/(n_i-1) = 3 \times \frac{1}{3} = 1\). - \(1/(N-k) = 1/9 \approx 0.1111111\).
Entonces: \[ C = 1 + \frac{1}{3(3-1)}\left(1 - \frac{1}{9}\right) = 1 + \frac{1}{6}\left(\frac{8}{9}\right) = 1 + \frac{8}{54} = 1 + 0.1481481 = 1.1481481. \]
Estadístico \(\chi_B^2\) y \(p\)-valor
Ahora: \[ \chi_B^2 = \frac{L}{C} = \frac{0.4009299}{1.1481481} = 0.349197\ (\text{aprox}). \]
Decisión (nivel \(\alpha=0.05\))
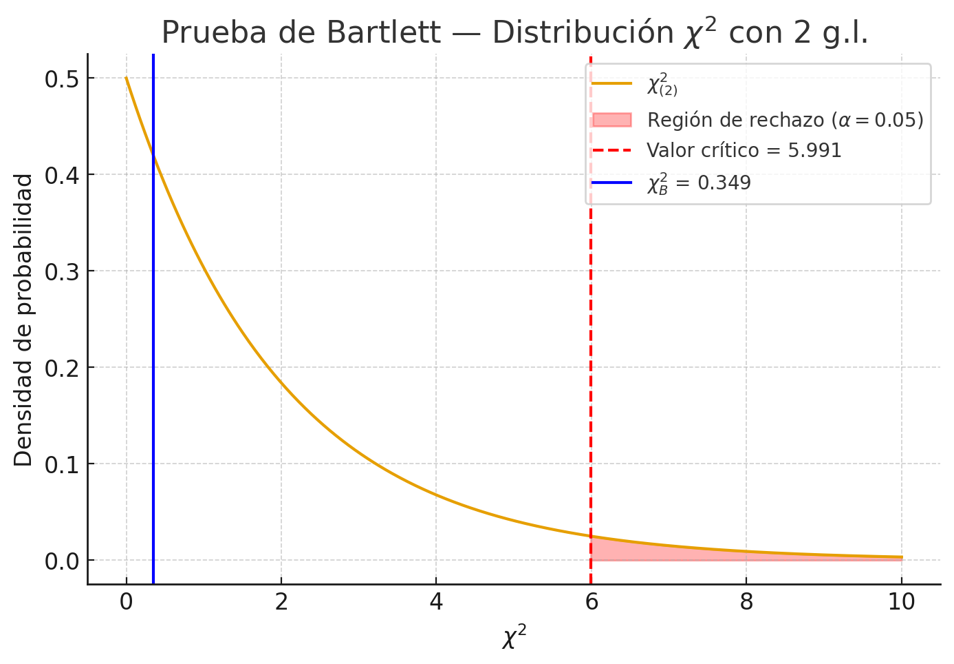
Interpretación: no hay evidencia estadística (con estos datos y bajo la suposición de normalidad) para afirmar que las varianzas poblacionales de los tratamientos difieran; la homogeneidad de varianzas no queda rechazada por Bartlett.
Prueba de rangos múltiples: LSD (Fisher)
Paso 1. Error cuadrático medio (ya calculado): \(MS_E = 1.2747861\).
Paso 2. Error estándar de la diferencia entre dos medias de tratamiento (RCBD, con \(b\) bloques): \[ SE(\bar y_{i\cdot}-\bar y_{i'\cdot}) = \sqrt{\frac{2 \cdot MS_E}{b}}. \]
Sustituyendo: \[ SE = \sqrt{\frac{2 \cdot 1.2747861}{4}} = \sqrt{0.63739305} = 0.798369. \]
Paso 3. Valor crítico \(t\) bilateral para \(\alpha=0.05\) y \(df_E=6\): \[ t_{0.975,6} = 2.446912. \]
Paso 4. Cálculo del LSD: \[ LSD = t_{0.975,6} \cdot SE = 2.446912 \times 0.798369 = 1.953539. \]
Paso 5. Comparaciones (medias por tratamiento): - \(\bar y_{A\cdot}=27.0725\)
- \(\bar y_{B\cdot}=22.9625\)
- \(\bar y_{C\cdot}=19.7400\)
Diferencias absolutas: - \(|A-B| = |27.0725-22.9625| = 4.1100 \ > LSD(1.9535)\) \(\Rightarrow\) Significativo. - \(|A-C| = |27.0725-19.7400| = 7.3325 \ > LSD\) \(\Rightarrow\) Significativo. - \(|B-C| = |22.9625-19.7400| = 3.2225 \ > LSD\) \(\Rightarrow\) Significativo.
Conclusión del LSD: las tres medias difieren significativamente por pares (A > B > C) en este ejemplo.
Conclusión general
El análisis ANOVA muestra un efecto claro de los tratamientos: \(F_{Tr}=42.38\) (con \((2,6)\) gl), por lo que rechazamos \(H_0\) y concluimos que las enmiendas difieren en la reducción de TPH.
El bloque también aporta variación (\(F_B=4.01\)), lo que respalda la elección del DBCA.
Los residuos satisfacen la normalidad
La eficiencia relativa indica que usar bloques redujo el error aproximadamente a la mitad (\(ER\approx 2.00\)) con respecto a un CRD sin bloqueo
La prueba LSD muestra que todas las comparaciones entre pares de tratamientos son significativas: \(A>B>C\) en reducción porcentual de TPH (A mejor que B; B mejor que C).
Solución del mismo problema con R
Preparación del entorno y datos
Paquetes necesarios
Creación del dataframe de datos
datos <- data.frame(
Bloque = rep(1:4, each=3),
Trat = rep(c("A","B","C"), times=4),
y = c(26.99,23.72,22.30,
27.05,21.53,18.53,
28.66,25.03,19.56,
25.59,21.57,18.57)
)
datos Bloque Trat y
1 1 A 26.99
2 1 B 23.72
3 1 C 22.30
4 2 A 27.05
5 2 B 21.53
6 2 C 18.53
7 3 A 28.66
8 3 B 25.03
9 3 C 19.56
10 4 A 25.59
11 4 B 21.57
12 4 C 18.57Tabla ANOVA
Df Sum Sq Mean Sq F value Pr(>F)
Trat 2 108.06 54.03 42.38 0.000289 ***
factor(Bloque) 3 15.34 5.11 4.01 0.069777 .
Residuals 6 7.65 1.27
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Cálculo de eficiciencia relativa
Verificación de supuestos
Normalidad
Shapiro-Wilk normality test
data: res
W = 0.97514, p-value = 0.9566Homogeneidad de varianzas (Bartlett)
Diagnósticos gráficos
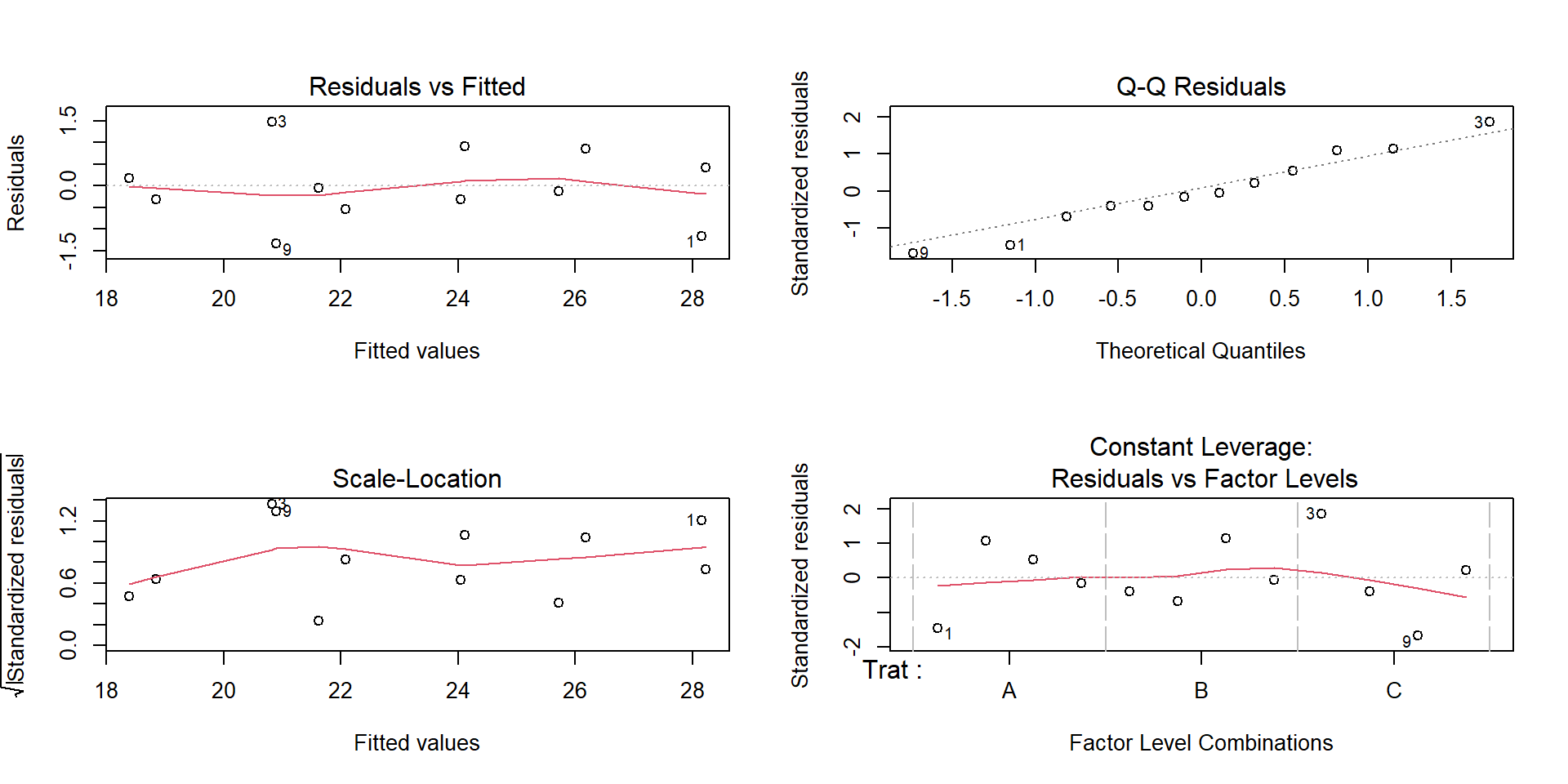
Prueba LSD
# Usamos el error del modelo RCBD (residual del aov con bloque)
lsd_out <- LSD.test(modelo, "Trat", group = FALSE, p.adj = "none", console = TRUE)
Study: modelo ~ "Trat"
LSD t Test for y
Mean Square Error: 1.274786
Trat, means and individual ( 95 %) CI
y std r se LCL UCL Min Max Q25 Q50
A 27.0725 1.255027 4 0.5645321 25.69114 28.45386 25.59 28.66 26.64 27.020
B 22.9625 1.716535 4 0.5645321 21.58114 24.34386 21.53 25.03 21.56 22.645
C 19.7400 1.771910 4 0.5645321 18.35864 21.12136 18.53 22.30 18.56 19.065
Q75
A 27.4525
B 24.0475
C 20.2450
Alpha: 0.05 ; DF Error: 6
Critical Value of t: 2.446912
Comparison between treatments means
difference pvalue signif. LCL UCL
A - B 4.1100 0.0021 ** 2.156461 6.063539
A - C 7.3325 0.0001 *** 5.378961 9.286039
B - C 3.2225 0.0068 ** 1.268961 5.176039Grupos
Study: modelo ~ "Trat"
LSD t Test for y
Mean Square Error: 1.274786
Trat, means and individual ( 95 %) CI
y std r se LCL UCL Min Max Q25 Q50
A 27.0725 1.255027 4 0.5645321 25.69114 28.45386 25.59 28.66 26.64 27.020
B 22.9625 1.716535 4 0.5645321 21.58114 24.34386 21.53 25.03 21.56 22.645
C 19.7400 1.771910 4 0.5645321 18.35864 21.12136 18.53 22.30 18.56 19.065
Q75
A 27.4525
B 24.0475
C 20.2450
Alpha: 0.05 ; DF Error: 6
Critical Value of t: 2.446912
least Significant Difference: 1.953539
Treatments with the same letter are not significantly different.
y groups
A 27.0725 a
B 22.9625 b
C 19.7400 c y groups
A 27.0725 a
B 22.9625 b
C 19.7400 cReferencias
Gutiérrez Pulido, H., & de la Vara Salazar, R. (2008). Análisis y diseño de experimentos (2ª ed.). McGraw-Hill/Interamericana Editores.
Montgomery, D. C. (2017). Design and analysis of experiments (8th ed.). John Wiley & Sons.
Quinn, G. P., & Keough, M. J. (2002). Experimental design and data analysis for biologists (2nd ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511806384