La familia de diseños factoriales completos \(2^k\) (k factores con dos niveles) es de las más utilizadas en investigación e industria por su eficacia y versatilidad.
Útiles principalmente cuando \(2 \leq k \leq 5\) (de 4 a 32 tratamientos, manejables en la práctica).
Cuando \(k > 5\), se recomienda un factorial fraccionado \(2^{k-p}\) para reducir el número de corridas.
Tanto completos como fraccionados, los factoriales en dos niveles son el núcleo de las aplicaciones modernas del diseño de experimentos.
Número de réplicas en \(2^k\) — idea clave
El número de corridas crece exponencialmente: con \(r\) réplicas → \(r\cdot 2^k\) corridas.
En práctica, la mayoría de estudios \(2^k\) (o fracciones) usan \(\leq 32\) corridas; incluso \(\leq 16\) suele bastar en una primera etapa.
Para \(k\ge 5\) conviene fraccionar (\(2^{k-p}\)) y, si es necesario, completar después.
Guía rápida (corridas típicas)
Diseño
Recomendación inicial
Corridas típicas
\(2^2\)
\(3\)–\(4\) réplicas
\(12\), \(16\)
\(2^3\)
\(2\) réplicas
\(16\)
\(2^4\)
\(1\)–\(2\) réplicas
\(16\), \(32\)
\(2^5\)
Fracción\(2^{5-1}\) (media fracción); evaluar y luego completar si hace falta
\(16\), \(32\)
\(2^6\)
Fracción\(2^{6-2}\) o \(2^{6-1}\)
\(16\), \(32\)
\(2^7\)
Fracción\(2^{7-3}\) o \(2^{7-2}\)
\(16\), \(32\)
\(2^4\) es el completo más grande que suele correrse con \(2\) réplicas (32 corridas).
Para \(k>8\), fracciones con \(\leq 32\) corridas siguen siendo útiles para “tamizado”.
Si solo hay 1 réplica: cómo obtener el error (ANOVA aproximado)
En \(2^k\) no replicado, estima \(SS_E\)aglomerando efectos pequeños (típicamente interacciones de orden \(\ge 3\)) al error.
Pasos: (1) Enviar a error interacciones altas si son despreciables (verificación gráfica/tabular); (2) añadir otros efectos claramente pequeños hasta tener un error estable.
Fórmulas: \(SS_E=\sum SS_{\text{efectos\ enviados}}\), \(\;\;gl_E=\#\text{efectos\ enviados}\); compara \(CM_E\) con una varianza histórica para validar orden de magnitud.
Regla práctica: reunir ≥ 8 efectos pequeños ayuda a estabilizar el \(CM_E\); cuidado con mandar efectos reales al error (inflan \(CM_E\)) o con un error subestimado (falsos positivos).
Diseño \(2^2\)
Introducción al diseño \(2^2\)
El diseño factorial \(2^2\) es el más sencillo de la familia de diseños \(2^k\).
Se caracteriza por trabajar con dos factores, cada uno en dos niveles: bajo (−) y alto (+).
Este diseño constituye la base para comprender los diseños factoriales de mayor dimensión.
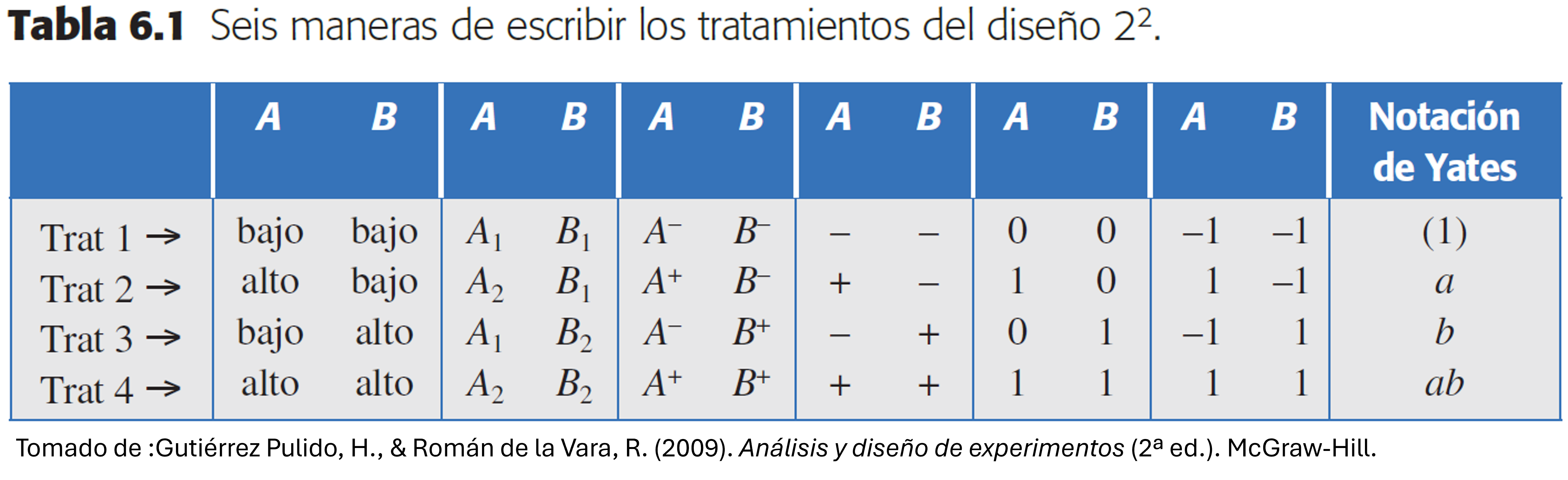
Notaciones: signos, letras y Yates
- La notación con letras (A+, A−) se emplea para identificar el punto ganador (mejor tratamiento).
La notación de signos (+, −) es muy práctica para escribir las matrices de diseño.
la notación de Yates, permite representar y calcular fácilmente los efectos de interés.
Regla: Si una letra minúscula aparece → el factor correspondiente está en su nivel alto. Si no aparece → el factor está en su nivel bajo.
Ejemplo: ab indica que A y B están ambos en alto.
Representación geométrica de un diseño \(2^2\)
Cada vértice corresponde a un punto de diseño o tratamiento dentro del experimento.
El área delimitada por el cuadrado se denomina región experimental y representa el espacio en el que se evalúan los factores y niveles considerados. En consecuencia, las conclusiones derivadas del experimento tienen validez, en principio, únicamente dentro de esta región.
Cálculo de los efectos
En este diseño hay tres efectos de interés: los dos efectos principales (\(A\) y \(B\)) y la interacción (\(AB\)).
Con la notación de Yates, si cada tratamiento se corre \(n\) veces:
La suma de cuadrados total (a partir de observaciones) es: \[
SS_T=\sum_{i=1}^{2}\sum_{j=1}^{2}\sum_{\ell=1}^{n} Y_{ij\ell}^{\,2}\;-\;\frac{Y_{\cdots}^{\,2}}{n\,2^2},
\] donde \(Y_{\cdots}=\sum_{i,j,\ell} Y_{ij\ell}\).
El error: \[
SS_E = SS_T-SS_A-SS_B-SS_{AB}.
\]
Equivalentemente, con contrastes\(C_A=(a+ab)-[(1)+b]\), \(C_B=(b+ab)-[(1)+a]\), \(C_{AB}=(ab+(1))-(a+b)\):
\(F_0\) se compara con el valor crítico \(F_{(1,\,4(n-1))}\).
Si \(F_0 > F_{\alpha}\), se rechaza \(H_0\) para ese efecto.
Se rechaza \(H_0\) si el valor-p < \(\alpha\)
Ejemplo
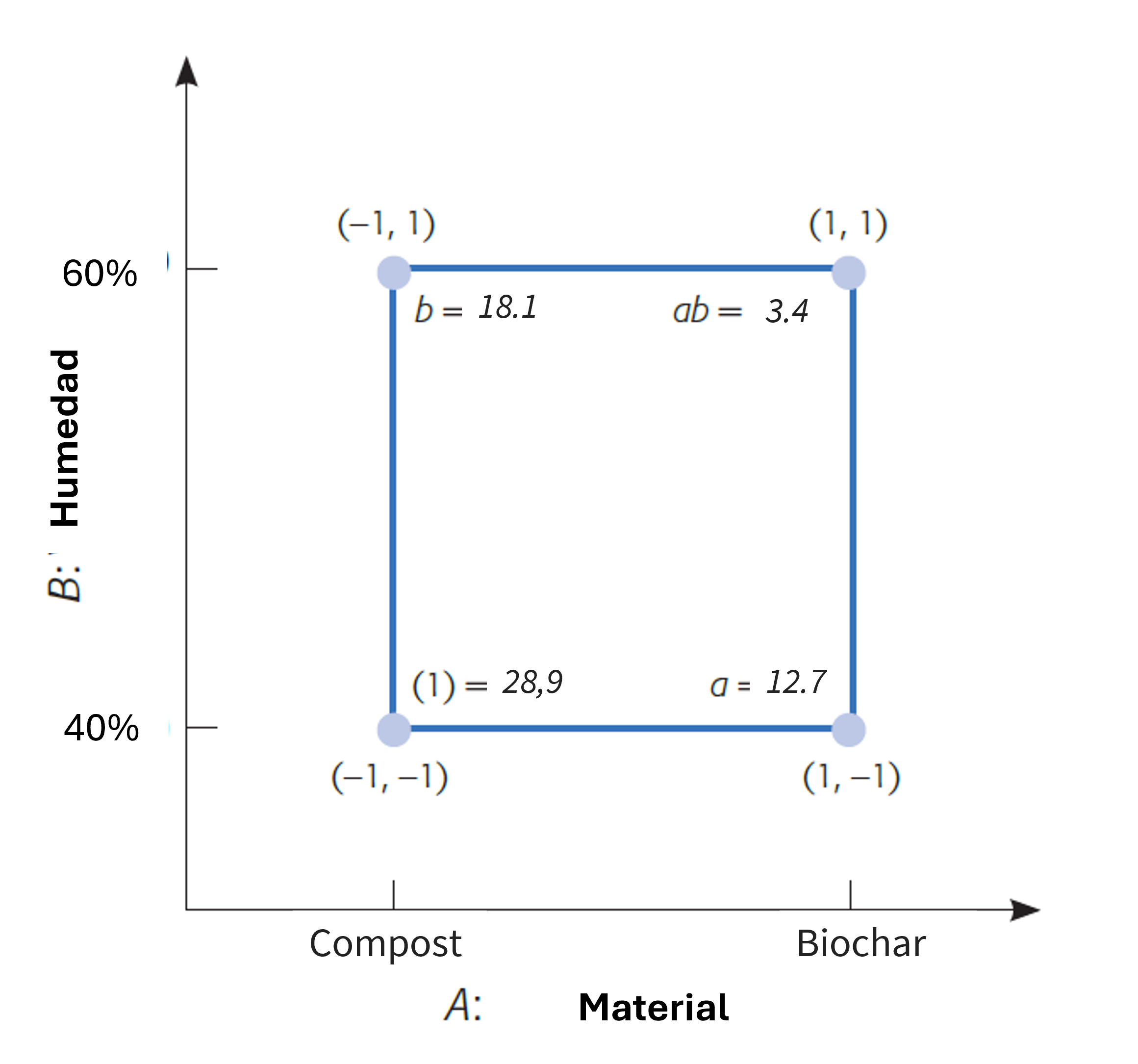
Contexto y objetivo. En una planta de compostaje se evaluará, en biofiltro de laboratorio, el efecto del material de lecho y de la humedad sobre la concentración de H\(_2\)S a la salida (ppmv), y si existe interacción entre factores.
Factores (codificación \(\pm1\)). - A — Material del lecho: Compost (−1) vs Biochar (+1)
- B — Humedad del lecho:40 % (−1) vs 60 % (+1)
Respuesta.\(Y=\) H\(_2\)S (ppmv) a la salida (menor es mejor). Diseño. Factorial \(2\times2\) completamente al azar con \(n=4\) réplicas por celda (16 corridas); orden de corridas aleatorizado.
Condiciones controladas
Carga de entrada: \(C_{\text{in}}=20\pm2\) ppmv H₂S (mezclador dinámico).
Sensórica: celda electroquímica continua (verificación colorimétrica por azul de metileno 1/4 de réplicas).
Diseño, unidades y réplicas
Diseño completamente al azar 2×2 con 4 réplicas por celda (16 corridas).
Unidad experimental: 1 h de operación en estado cuasi-estacionario por tratamiento.
Reacondicionar humedad y estabilizar 20 min entre corridas.
Aleatorizar el orden de corridas para evitar deriva temporal.
Hipótesis a probar
Sea \(\mu_{ij}\) la media en el nivel \(i\) de \(A\) (material; \(i=1\) compost, \(i=2\) biochar) y nivel \(j\) de \(B\) (humedad; \(j=1\) 40%, \(j=2\) 60%). También: \(Y=\beta_0+\beta_A x_A+\beta_B x_B+\beta_{AB}x_Ax_B+\varepsilon\) con \(x_A,x_B\in\{-1,+1\}\).
En este primer paso generamos el diseño factorial \(2^2\) con 4 réplicas por celda (16 corridas en total) usando FrF2. Definimos los nombres y niveles de los factores exactamente como en el ejemplo aplicado (Material y Humedad). No aleatorizamos para poder asignar manualmente las réplicas en el mismo orden que aparece en la tabla.
Etiquetamos cada fila del diseño con la notación de Yates “(1)”, “a”, “b”, “ab” y, aparte, creamos un objeto con los vectores de respuesta (4 réplicas por tratamiento) exactamente como en tu tabla. Esto nos permitirá asignar la respuesta a las filas correctas.
Code
# 2) Etiqueta de tratamiento en notación de Yates para cada fila del diseñoyates_lab <-with(des, ifelse(Material=="Compost(-)"& Humedad=="40%(-)", "(1)",ifelse(Material=="Biochar(+)"& Humedad=="40%(-)", "a",ifelse(Material=="Compost(-)"& Humedad=="60%(+)", "b", "ab"))))des$Yates <-factor(yates_lab, levels =c("(1)","a","b","ab"))y_list <-list("(1)"=c(7.6, 7.1, 6.8, 7.4), # A-, B-"a"=c(3.2, 2.9, 3.5, 3.1), # A+, B-"b"=c(4.8, 4.2, 4.5, 4.6), # A-, B+"ab"=c(0.9, 0.7, 1.0, 0.8) # A+, B+)y_list
Aquí asignamos cada réplica de y_list en las 4 filas correspondientes de des (según su etiqueta de Yates). Luego verificamos totales y medias por tratamiento: deben coincidir con \((1)=28.9,\ a=12.7,\ b=18.1,\ ab=3.4\) y con las medias mostradas en la tabla.
Code
## 4) Asignación robusta: coloca cada réplica en las filas correspondientes del diseñodes$y <-NA_real_for (k innames(y_list)) { idx <-which(des$Yates == k) # deben ser 4 índices por tratamiento des$y[idx] <- y_list[[k]] # asigna sus 4 réplicas (en el orden de las filas)}## Verificación de totales y medias en Yatestapply(des$y, des$Yates, sum) # (1)=28.9, a=12.7, b=18.1, ab=3.4
run.no run.no.std.rp Material Humedad Blocks Yates y
1 1 1.1 Compost(-) 40%(-) .1 (1) 7.6
2 2 2.1 Biochar(+) 40%(-) .1 a 3.2
3 3 3.1 Compost(-) 60%(+) .1 b 4.8
4 4 4.1 Biochar(+) 60%(+) .1 ab 0.9
5 5 1.2 Compost(-) 40%(-) .2 (1) 7.1
6 6 2.2 Biochar(+) 40%(-) .2 a 2.9
7 7 3.2 Compost(-) 60%(+) .2 b 4.2
8 8 4.2 Biochar(+) 60%(+) .2 ab 0.7
9 9 1.3 Compost(-) 40%(-) .3 (1) 6.8
10 10 2.3 Biochar(+) 40%(-) .3 a 3.5
11 11 3.3 Compost(-) 60%(+) .3 b 4.5
12 12 4.3 Biochar(+) 60%(+) .3 ab 1.0
13 13 1.4 Compost(-) 40%(-) .4 (1) 7.4
14 14 2.4 Biochar(+) 40%(-) .4 a 3.1
15 15 3.4 Compost(-) 60%(+) .4 b 4.6
16 16 4.4 Biochar(+) 60%(+) .4 ab 0.8
class=design, type= full factorial
NOTE: columns run.no and run.no.std.rp are annotation,
not part of the data frame
Ajustamos un modelo aov con efectos principales e interacción (Material*Humedad). La salida summary(fit) debe reflejar lo obtenido en el cálculo manual: efectos muy significativos de A y B y no significativo para la interacción AB con estos datos.
Code
fit <-aov(y ~ Material * Humedad, data = des)summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
Material 1 59.68 59.68 903.606 1.15e-12 ***
Humedad 1 25.25 25.25 382.344 1.82e-10 ***
Material:Humedad 1 0.14 0.14 2.129 0.17
Residuals 12 0.79 0.07
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Diagnóstico visual de efectos.
Para reproducir las gráficas de efectos e interacción del enfoque clásico, usamos IAPlot (interacción) y, si lo deseas, MEPlot (efectos principales).
Note
Nota clave: estas funciones requieren declarar la respuesta con response = “y”; de lo contrario aparece el error “The design obj must have at least one response.”
Efectos principales
Code
EP <-MEPlot(fit, response ="y") # Efectos principales
Code
head(EP)
Material Humedad
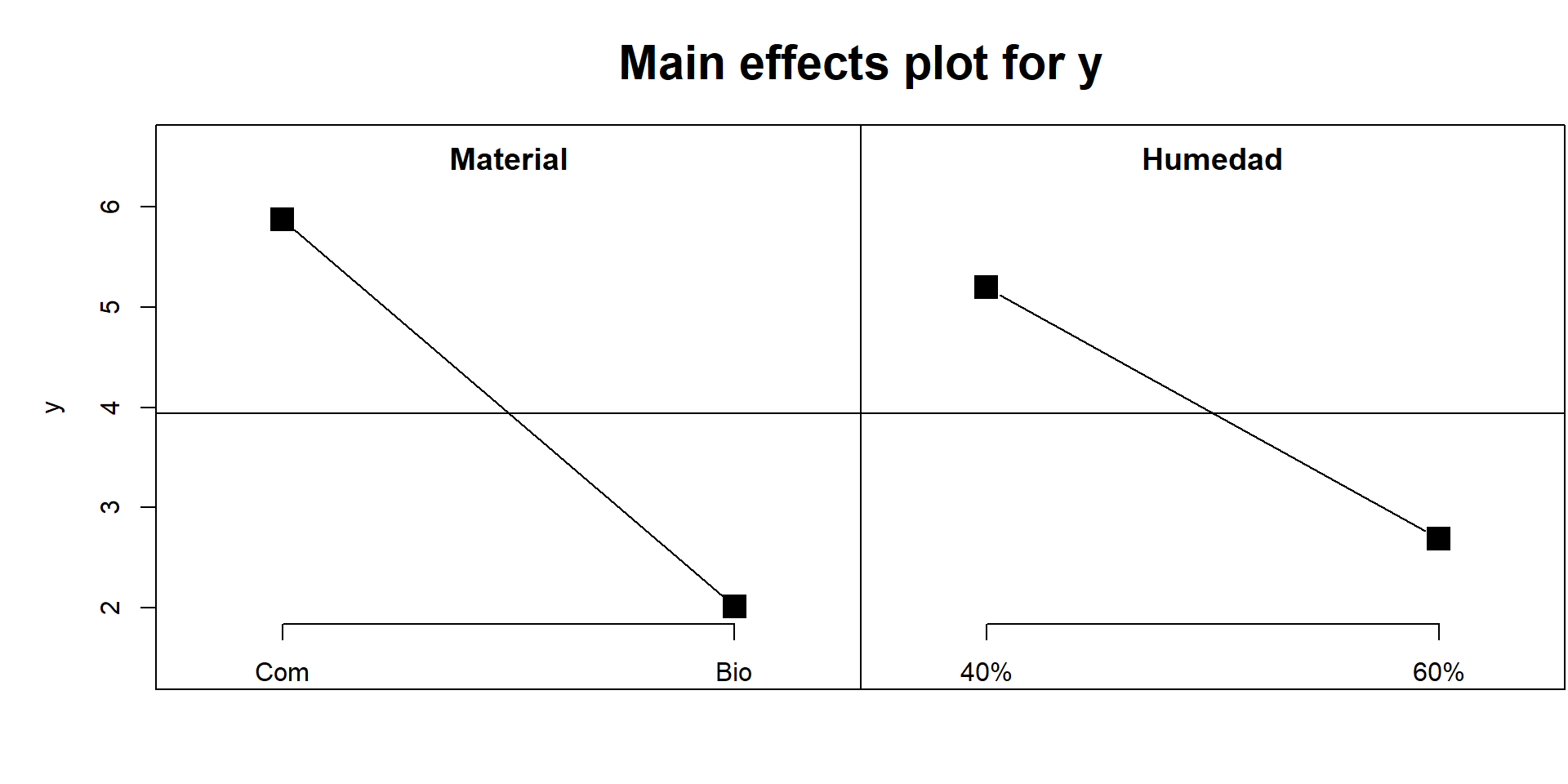
- 5.8750 5.2000
+ 2.0125 2.6875
Interpretación breve de los efectos principales
Material: al pasar de Compost a Biochar la media baja de ~5.88 a ~2.02 ppmv (Δ ≈ −3.86). → Efecto principal muy fuerte; Biochar rinde mejor en promedio.
Humedad: al pasar de 40% a 60% la media baja de ~5.21 a ~2.69 ppmv (Δ ≈ −2.52). → Efecto marcado, aunque menor que el del material.
En este gráfico las pendientes negativas en ambos paneles indican que moverse al nivel “alto” (Biochar; 60%) reduce la respuesta (y = H₂S, menor es mejor).
Conclusión práctica: los mejores niveles, considerados por separado, son Biochar y 60%. En combinación (ver celdas), esto coincide con la menor media observada (Biochar–60%).
Efecto de interacción
Code
EI <-IAPlot(fit, response ="y") # Efecto de interacción
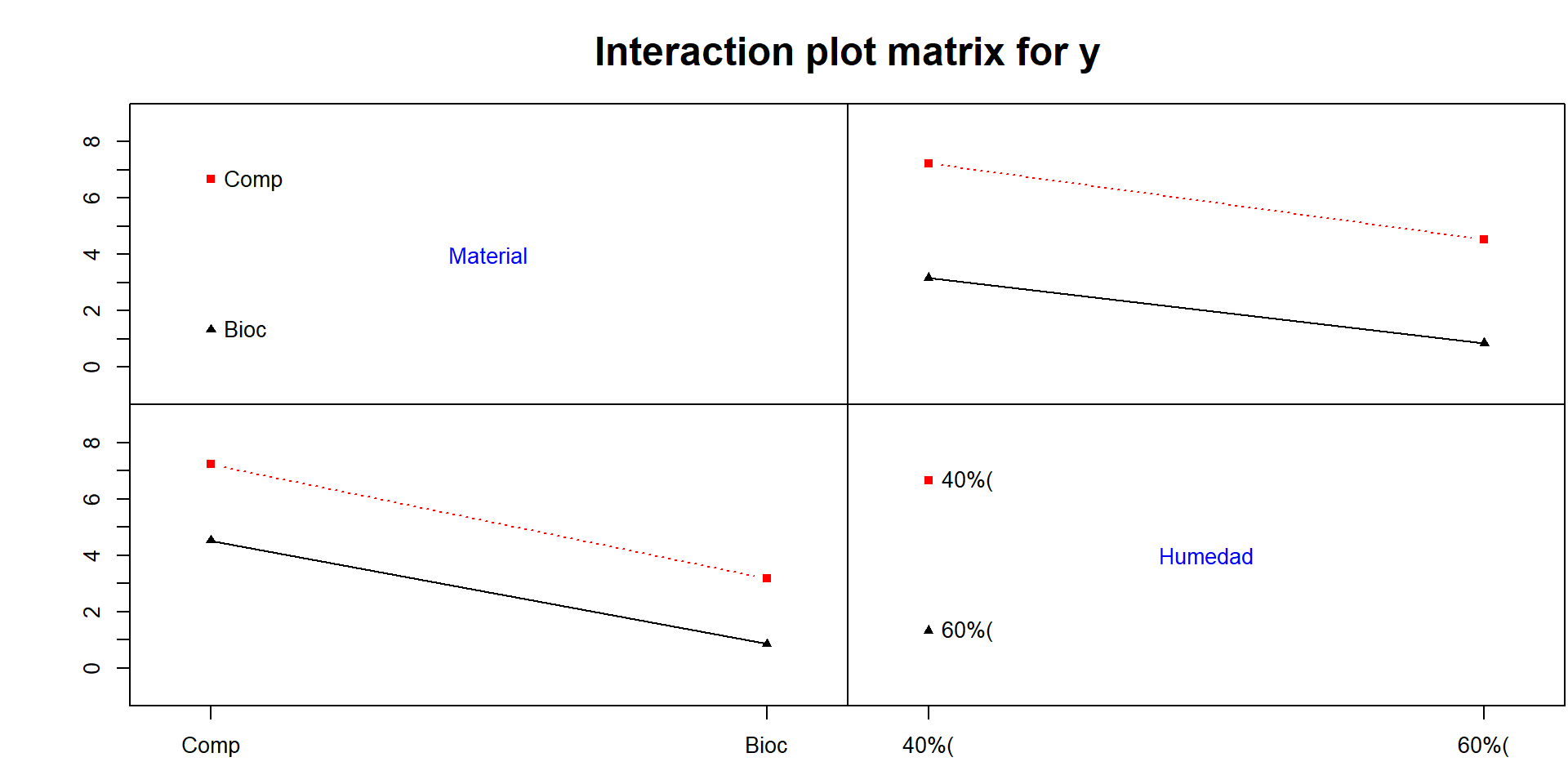
Las líneas son casi paralelas en ambos contrastes → la interacción AB es débil/no significativa (coincide con ANOVA: p ≈ 0.17).
En los dos factores, la pendiente es descendente al pasar al nivel alto (Biochar; 60%) → cada factor reduce y por sí mismo.
No hay cruce de líneas (no se invierte el orden entre niveles) → el efecto conjunto no cambia la dirección del efecto principal.
Mejor combinación esperada: Biochar–60%, que produce la menor media observada de y (H₂S, menor es mejor).
Verificación de Supuestos
Code
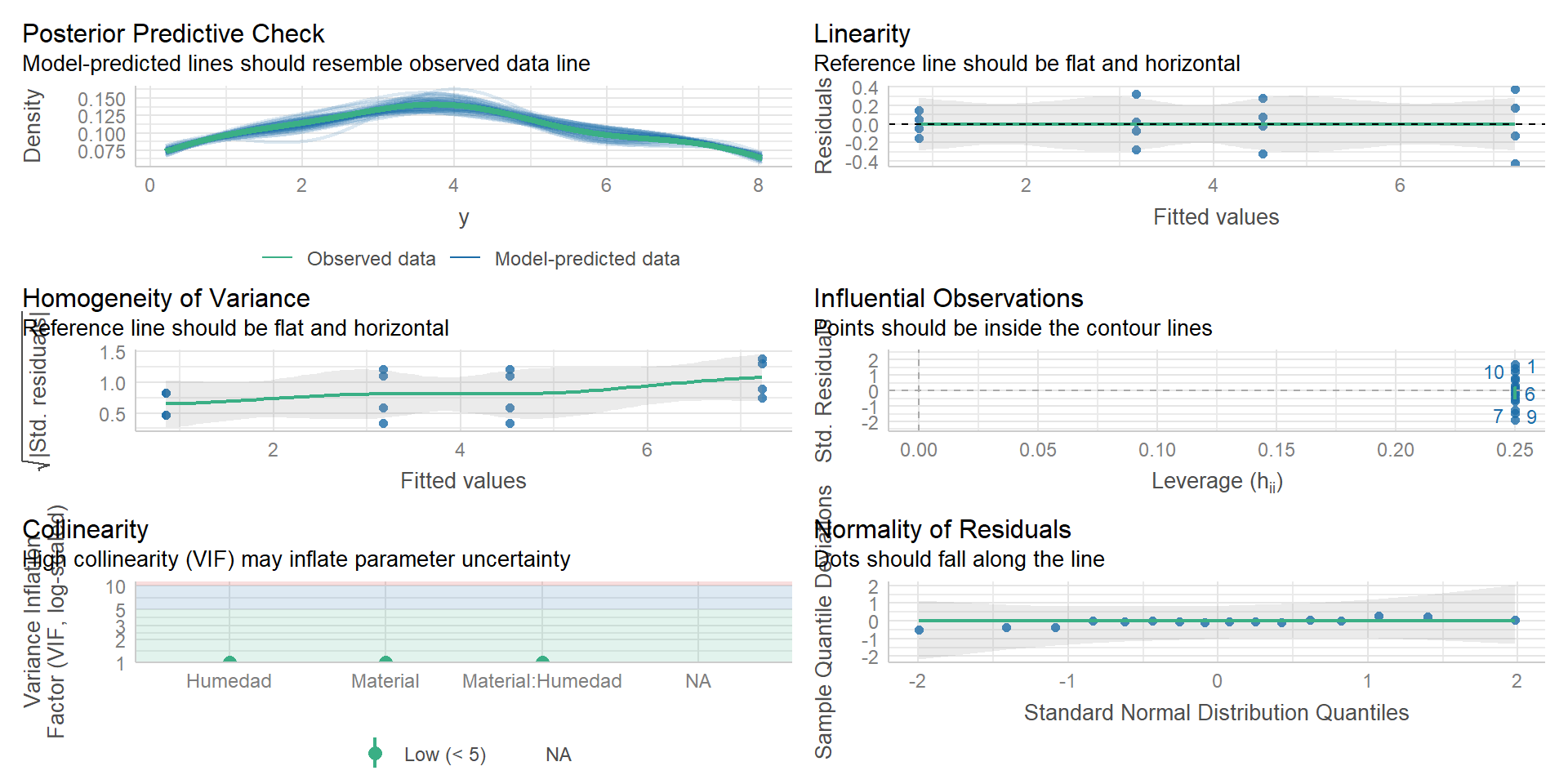
library(performance)performance::check_model(fit)
Verificación de supuestos — resumen
Normalidad: QQ-plot cercano a la línea de referencia → residuos ~ normales.
Linealidad: residuales sin patrón respecto a ajustados → relación lineal plausible.
Homoscedasticidad: ligera pendiente en escala-ubicación, pero débil → varianza aproximadamente constante.
Influyentes: sin puntos fuera de las bandas de Cook/leverage → no hay observaciones problemáticas.
Colinealidad: VIF bajos (< 2) → sin colinealidad relevante.
Independencia: respaldada por la aleatorización del experimento.
Conclusión: supuestos del ANOVA razonablemente satisfechos; no se requieren transformaciones.
Verificación de Supuestos
Code
check_normality(fit)
OK: residuals appear as normally distributed (p = 0.972).
Code
check_homogeneity(fit, method ="bartlett") # podria cambiar a method = "levene"
OK: There is not clear evidence for different variances across groups (Bartlett Test, p = 0.514).
Modelo de regresión
En un diseño \(2^k\), es útil ajustar un modelo de regresión sobre variables codificadas\(x_1,\dots,x_k \in \{-1,+1\}\) para predecir la respuesta \(Y\) en cualquier punto de la región experimental.
Para \(k=2\) (factores \(A\) y \(B\)), el modelo lineal con interacción es:
La codificación unitaria (\(-1,+1\)) hace que los coeficientes sean los efectos estimados divididos entre 2: \(\beta_A=\tfrac{\text{Efecto}(A)}{2}\), \(\;\beta_B=\tfrac{\text{Efecto}(B)}{2}\), \(\;\beta_{AB}=\tfrac{\text{Efecto}(AB)}{2}\).
El término \(\beta_0\) es la media global (predicción en el centro, \(x_A=x_B=0\)).
Tip
¿Por qué “efecto/2”?
Con \(x\in\{-1,+1\}\) el ancho de la región es 2 unidades; dividir por 2 lleva los efectos a escala unitaria, que es la escala usual de regresión.
Calidad del ajuste: \(R^2\) y \(R^2_{\text{aj}}\)
Evaluamos la capacidad explicativa del modelo con:
donde \(SS_E\) y \(SS_T\) son la suma de cuadrados del error y total; \(CM_E = SS_E/\text{gl}_E\) y \(CM_T = SS_T/\text{gl}_T\). \(R^2_{\text{aj}}\) es preferible cuando hay varios términos, pues penaliza complejidad innecesaria.
Con el modelo ajustado, podemos predecir\(\hat Y\) e informar intervalos de confianza para la media en puntos de interés (p. ej., vértices y centro de la región).
Implementación en R
A continuación, ajustamos el modelo codificado (\(x_A,x_B\in\{-1,+1\}\)), verificamos la relación efectos ↔︎ coeficientes, reportamos \(R^2\) y \(R^2_{\text{aj}}\), generamos predicciones con IC y visualizamos la superficie de respuesta.
Code
# Variables codificadas ±1des$xA <-ifelse(des$Material =="Biochar(+)", +1, -1)des$xB <-ifelse(des$Humedad =="60%(+)" , +1, -1)# Modelo de regresión con interacción en codificación unitarialm_cod <-lm(y ~ xA * xB, data = des)summary(lm_cod)
Call:
lm.default(formula = y ~ xA * xB, data = des)
Residuals:
Min 1Q Median 3Q Max
-0.4250 -0.1313 0.0000 0.1562 0.3750
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.94375 0.06425 61.385 2.31e-16 ***
xA -1.93125 0.06425 -30.060 1.15e-12 ***
xB -1.25625 0.06425 -19.554 1.82e-10 ***
xA:xB 0.09375 0.06425 1.459 0.17
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.257 on 12 degrees of freedom
Multiple R-squared: 0.9908, Adjusted R-squared: 0.9885
F-statistic: 429.4 on 3 and 12 DF, p-value: 1.806e-12
Efectos ↔︎ Coeficientes
Comprobamos la equivalencia: (efecto estimado) \(\approx 2\times\) (coeficiente de regresión). La tabla debe mostrar coincidencia numérica fila a fila.
Medimos la proporción de variabilidad explicada por el modelo. Reportamos también el ANOVA para ver \(SC_\text{modelo}\), \(SC_\text{error}\) y \(SC_\text{total}\).
Code
s <-summary(lm_cod)c(R2 = s$r.squared, R2_aj = s$adj.r.squared)
R2 R2_aj
0.9907698 0.9884622
Code
anova(lm_cod)
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
xA 1 59.676 59.676 903.6057 1.150e-12 ***
xB 1 25.251 25.251 382.3438 1.815e-10 ***
xA:xB 1 0.141 0.141 2.1293 0.1702
Residuals 12 0.792 0.066
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Predicciones con IC (vértices y centro)
Obtenemos la respuesta promedio predicha \(\hat Y\) y su IC 95% en los cuatro vértices y en el centro de la región experimental (\(x_A,x_B\in{-1,0,+1}\)).
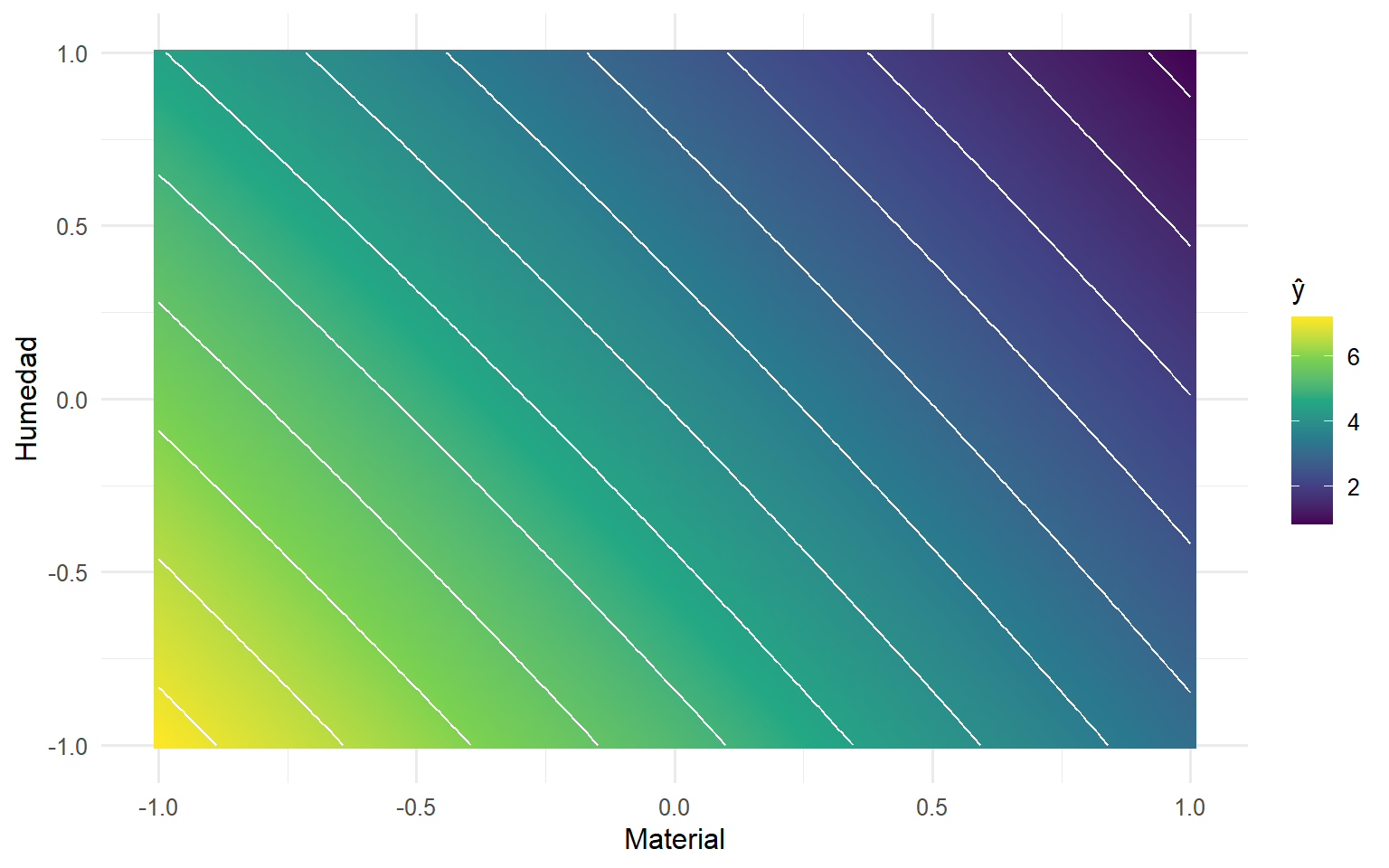
Visualizamos la superficie \(\hat Y(x_A,x_B)\) y sus contornos en \([-1,1]\times[-1,1]\). Busca el mínimo (zonas más frías) y verifica que coincida con la mejor combinación observada.
Superficie de respuesta (ŷ) y contornos en la región experimental codificada.
Superficie de respuesta — interpretación
Al avanzar hacia Biochar (+1) y 60% (+1) el color pasa de amarillo a morado ⇒ la respuesta disminuye (menor H₂S = mejor).
Las isolíneas rectas y paralelas sugieren interacción pequeña (modelo casi aditivo/planar).
La pendiente es mayor en Material (xA) que en Humedad (xB) ⇒ el Material tiene mayor efecto.
Óptimo: Biochar–60% ((+1,+1)), Máximo: Compost–40% ((-1,-1)); en el centro ((0,0)) se predice ŷ ≈ 3.94.
Code
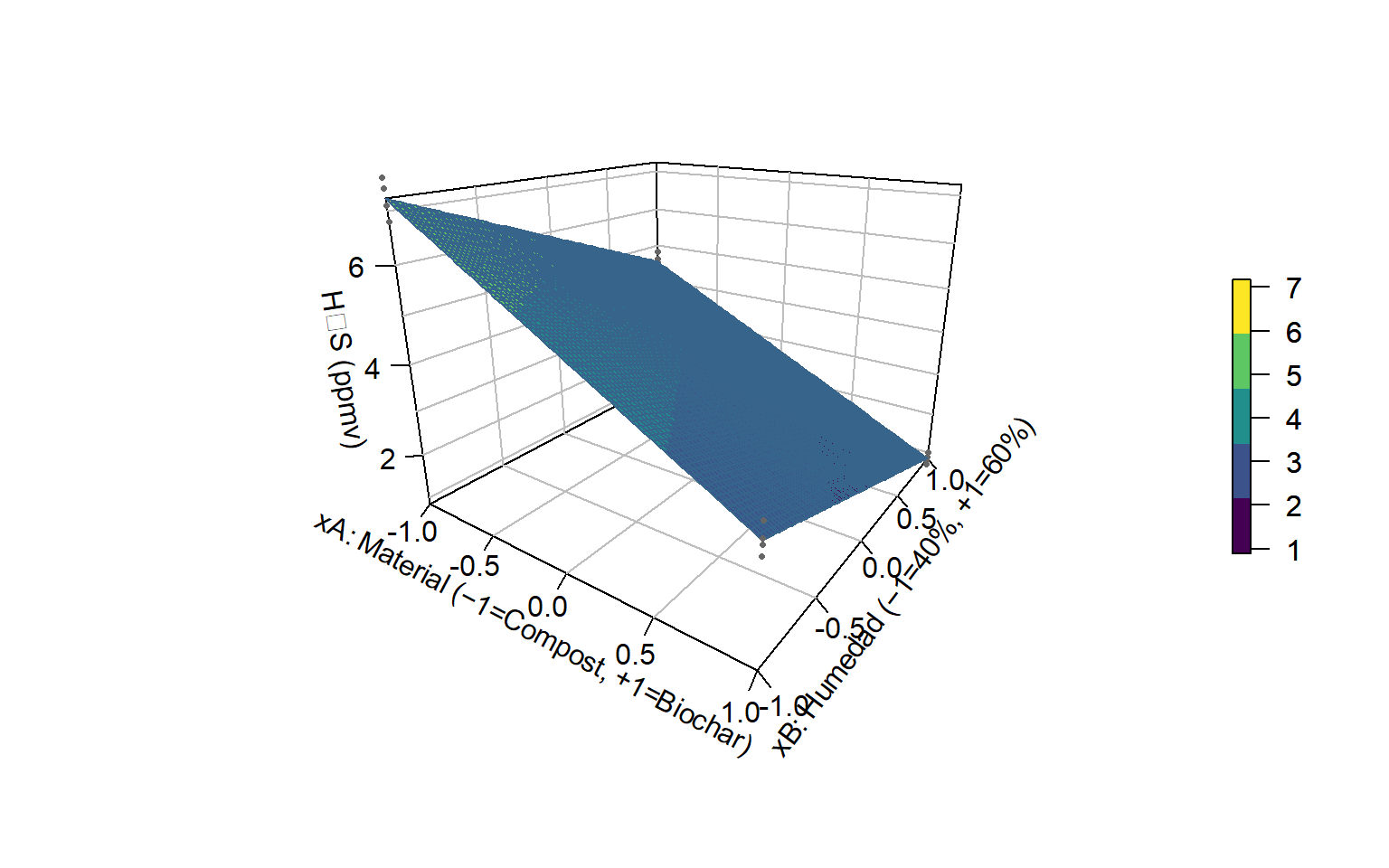
library(plot3D)library(viridisLite)# Paleta: usa viridisLite si está disponible; si no, jet.colif (!requireNamespace("viridisLite", quietly =TRUE)) { pal <- plot3D::jet.col(5) # fallback} else { pal <- viridisLite::viridis(5) # oscuro (bajo) → claro (alto)}# Malla en [-1,1] × [-1,1]x <-seq(-1, 1, length.out =80) # -1 = Compost, +1 = Biochary <-seq(-1, 1, length.out =80) # -1 = 40%, +1 = 60%G <-mesh(x, y)# Predicciones del modelo codificadoz_hat <-predict(lm_cod, newdata =data.frame(xA =c(G$x), xB =c(G$y)))Z <-matrix(z_hat, nrow =nrow(G$x), ncol =ncol(G$y))# Superficie + contornossurf3D(x = G$x, y = G$y, z = Z,colvar = Z, col = pal,border ="steelblue4", lwd =1.1,lighting =FALSE, bty ="b2", box =TRUE, ticktype ="detailed",xlab ="xA: Material (−1=Compost, +1=Biochar)",ylab ="xB: Humedad (−1=40%, +1=60%)",zlab ="H₂S (ppmv)",theta =35, phi =20, expand =0.8,colkey =list(side =4, length =0.5, width =0.45, clab ="ŷ"),contour =list(nlevels =8, col ="grey",side =c("z","bottom","left")))# Puntos observadosscatter3D(x = des$xA, y = des$xB, z = des$y,add =TRUE, pch =16, cex =0.5, col ="grey40")
Superficie estimada (ŷ) con contornos proyectados y puntos observados.
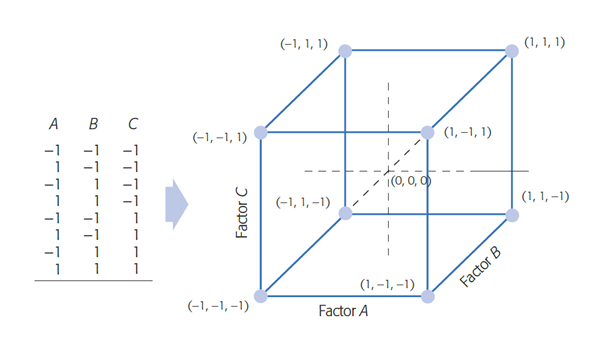
Diseño \(2^3\)
Introducción al diseño \(2^3\)
En un \(2^3\) estudiamos tres factores\((A,B,C)\) con dos niveles cada uno \((−1,+1)\) → 8 tratamientos (vértices de un cubo en la región experimental). Podemos estimar \(2^3-1=7\) efectos: tres principales (\(A,B,C\)), tres interacciones dobles (\(AB,AC,BC\)) y la triple (\(ABC\)). La notación de Yates para los totales de tratamiento sigue el orden estándar: \((1),a,b,ab,c,ac,bc,abc\).
Efectos y contrastes en \(2^3\)
Con \(n\) réplicas por tratamiento, el efecto de cada término es el contraste dividido por \(2^{k-1}n=4n\): \(\;\;\displaystyle \text{Efecto}=\dfrac{C}{4n}\). La suma de cuadrados por término se obtiene como: \(\;\;\displaystyle SS=\dfrac{C^2}{2^k n}=\dfrac{C^2}{8n}\).
\(H_0: \beta_A=0 \quad\) vs \(\quad H_A: \beta_A\neq 0\)
\(H_0: \beta_B=0 \quad\) vs \(\quad H_A: \beta_B\neq 0\)
\(H_0: \beta_C=0 \quad\) vs \(\quad H_A: \beta_C\neq 0\)
Interacciones de segundo orden
\(H_0: \beta_{AB}=0 \quad\) vs \(\quad H_A: \beta_{AB}\neq 0\)
\(H_0: \beta_{AC}=0 \quad\) vs \(\quad H_A: \beta_{AC}\neq 0\)
\(H_0: \beta_{BC}=0 \quad\) vs \(\quad H_A: \beta_{BC}\neq 0\)
Interacción triple
\(H_0: \beta_{ABC}=0 \quad\) vs \(\quad H_A: \beta_{ABC}\neq 0\)
ANOVA para \(2^3\) con \(n\) réplicas
Fuente de variación
Suma de cuadrados (\(SS\))
gl
Cuadrado medio (\(MS\))
Estadístico \(F\)
Factor A
\(SS_A = \dfrac{C_A^2}{8n}\)
1
\(MS_A = SS_A/1\)
\(F_A = MS_A/MS_E\)
Factor B
\(SS_B = \dfrac{C_B^2}{8n}\)
1
\(MS_B = SS_B/1\)
\(F_B = MS_B/MS_E\)
Factor C
\(SS_C = \dfrac{C_C^2}{8n}\)
1
\(MS_C = SS_C/1\)
\(F_C = MS_C/MS_E\)
Interacción AB
\(SS_{AB} = \dfrac{C_{AB}^2}{8n}\)
1
\(MS_{AB} = SS_{AB}/1\)
\(F_{AB} = MS_{AB}/MS_E\)
Interacción AC
\(SS_{AC} = \dfrac{C_{AC}^2}{8n}\)
1
\(MS_{AC} = SS_{AC}/1\)
\(F_{AC} = MS_{AC}/MS_E\)
Interacción BC
\(SS_{BC} = \dfrac{C_{BC}^2}{8n}\)
1
\(MS_{BC} = SS_{BC}/1\)
\(F_{BC} = MS_{BC}/MS_E\)
Interacción ABC
\(SS_{ABC} = \dfrac{C_{ABC}^2}{8n}\)
1
\(MS_{ABC} = SS_{ABC}/1\)
\(F_{ABC} = MS_{ABC}/MS_E\)
Error
\(SS_E\)
\(8(n-1)\)
\(MS_E = SS_E/[8(n-1)]\)
—
Total
\(SS_T\)
\(8n-1\)
—
—
Recordatorio de contrastes
\(C_A = (a+ab+ac+abc) - \big[(1)+b+c+bc\big]\)
\(C_B = (b+ab+bc+abc) - \big[(1)+a+c+ac\big]\)
\(C_C = (c+ac+bc+abc) - \big[(1)+a+b+ab\big]\)
\(C_{ABC} = (abc + (1)) - (a+b+c+ab+ac+bc)\)
Los contrastes de dos factores (\(C_{AB}, C_{AC}, C_{BC}\)) se definen de forma análoga.
Note
Para tener \(gl_E>0\) se requiere \(n\ge 2\). En un \(2^3\) con \(n\) réplicas, el error tiene \(\mathrm{gl}_E=8(n-1)\). - Con una sola réplica (\(n=1\)) ⇒ \(\mathrm{gl}_E=0\) ⇒ no se puede estimar \(CM_E\) ni hacer pruebas \(F\) del ANOVA clásico. - Para un ANOVA válido en \(2^3\), exige al menos\(n\ge 2\) (entonces \(\mathrm{gl}_E=8(n-1)\ge 8\)).
Ejemplo simulado
Contexto y objetivo
Contexto y objetivo. En una planta de compostaje se evaluará, en biofiltro de laboratorio, el efecto del material de lecho (A), de la humedad (B) y de la temperatura (C) sobre la concentración de H\(_2\)S a la salida (ppmv), y si existe interacción entre factores.
Factores (codificación \(\pm1\)). - A — Material del lecho: Compost (\(-1\)) vs Biochar (\(+1\))
- B — Humedad del lecho:40 % (\(-1\)) vs 60 % (\(+1\))
- C — Temperatura del lecho/gas:25 °C (\(-1\)) vs 35 °C (\(+1\))
Respuesta.\(Y=\) H\(_2\)S (ppmv) a la salida (menor es mejor). Diseño. Factorial \(2^3\) completamente al azar con \(n=3\) réplicas por celda (24 corridas); orden de corridas aleatorizado.
Condiciones controladas (mismas que antes)
Carga de entrada: \(C_{\text{in}}=20\pm2\) ppmv H₂S.
Caudal: \(20\ \text{m}^3\ \text{h}^{-1}\).
Temperatura del gas nominal 25±2 °C (C añade un contraste controlado).
# Cargar el paquete necesariolibrary(FrF2)# Datos ajustados para mejorar significancia de la interaccióndatos <-data.frame(Material =c(rep("Biochar", 16), rep("Compost", 16)),Humedad =rep(c(rep("40%", 8), rep("60%", 8)), 2),Temperatura =rep(c(rep("25°C", 4), rep("35°C", 4)), 4),Replicas =rep(c("Réplica 1", "Réplica 2", "Réplica 3", "Réplica 4"), 8),H2S =c(30, 30.1, 29.8, 30.2, 0.1, 0.1, 0.2, 0.2, 28, 28.1, 27.9, 28.2, 0.1, 0.1, 0.2, 0.3,8, 8.1, 8.2, 8.3, 20, 20.1, 20.2, 20.3, 9, 9.1, 9.2, 9.3, 21, 21.1, 21.2, 21.3))# Crear un diseño factorial 2^3 con los factores Material, Humedad y Temperaturadiseño <-FrF2(nruns =8, nfactors =3, replications =4, factor.names =c("Material", "Humedad", "Temperatura"))# Asignar los datos crudos de H2S a las réplicas del diseñodiseño$H2S <- datos$H2S# Ajustar el modelo ANOVA para los factores y la interacciónfit <-aov(H2S ~ Material * Humedad * Temperatura, data = diseño)# Resumen del análisis de varianzasummary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
Material 1 17 17.11 0.120 0.732
Humedad 1 20 19.53 0.138 0.714
Temperatura 1 18 17.70 0.125 0.727
Material:Humedad 1 155 154.88 1.090 0.307
Material:Temperatura 1 68 68.45 0.482 0.494
Humedad:Temperatura 1 0 0.00 0.000 1.000
Material:Humedad:Temperatura 1 237 236.53 1.665 0.209
Residuals 24 3409 142.04
Conclusiones a partir del ANOVA:
Según la tabla de ANOVA, Material, Humedad y Temperatura no tienen efectos estadísticamente significativos sobre la concentración de H₂S, ya que sus valores p son mayores que 0.05 (Material p = 0.28388, Humedad p = 0.15818, Temperatura p = 0.31360). Sin embargo, la interacción Material:Temperatura es significativa (p = 0.00535), lo que indica que la combinación de estos dos factores influye en la concentración de H₂S.
Efectos
Efectos principales
Code
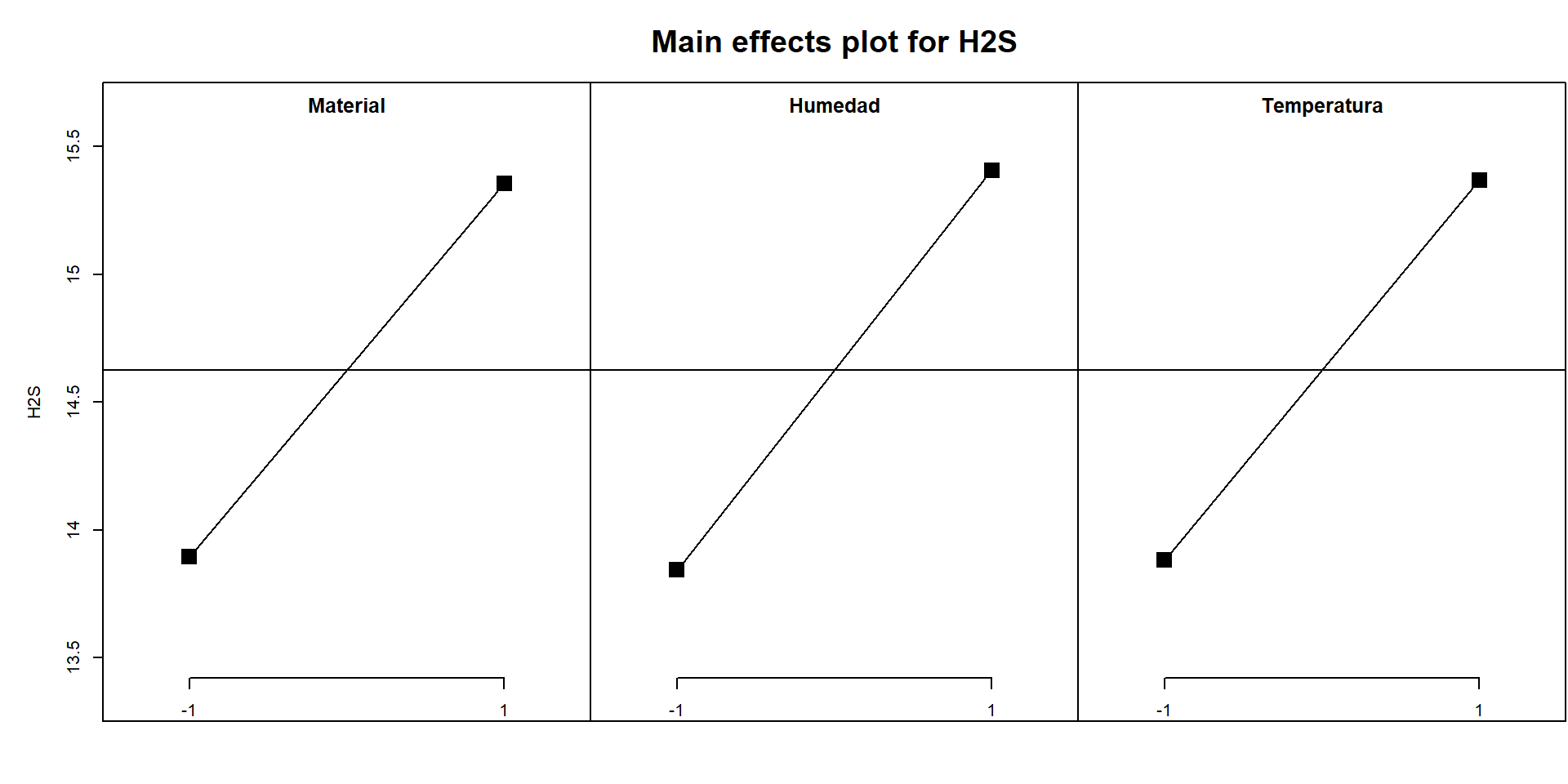
# Diagnóstico de los efectos principaleslibrary(ggplot2)EP <-MEPlot(fit, response ="H2S") # Efectos principales
Code
head(EP)
Material Humedad Temperatura
- 13.89375 13.84375 13.88125
+ 15.35625 15.40625 15.36875
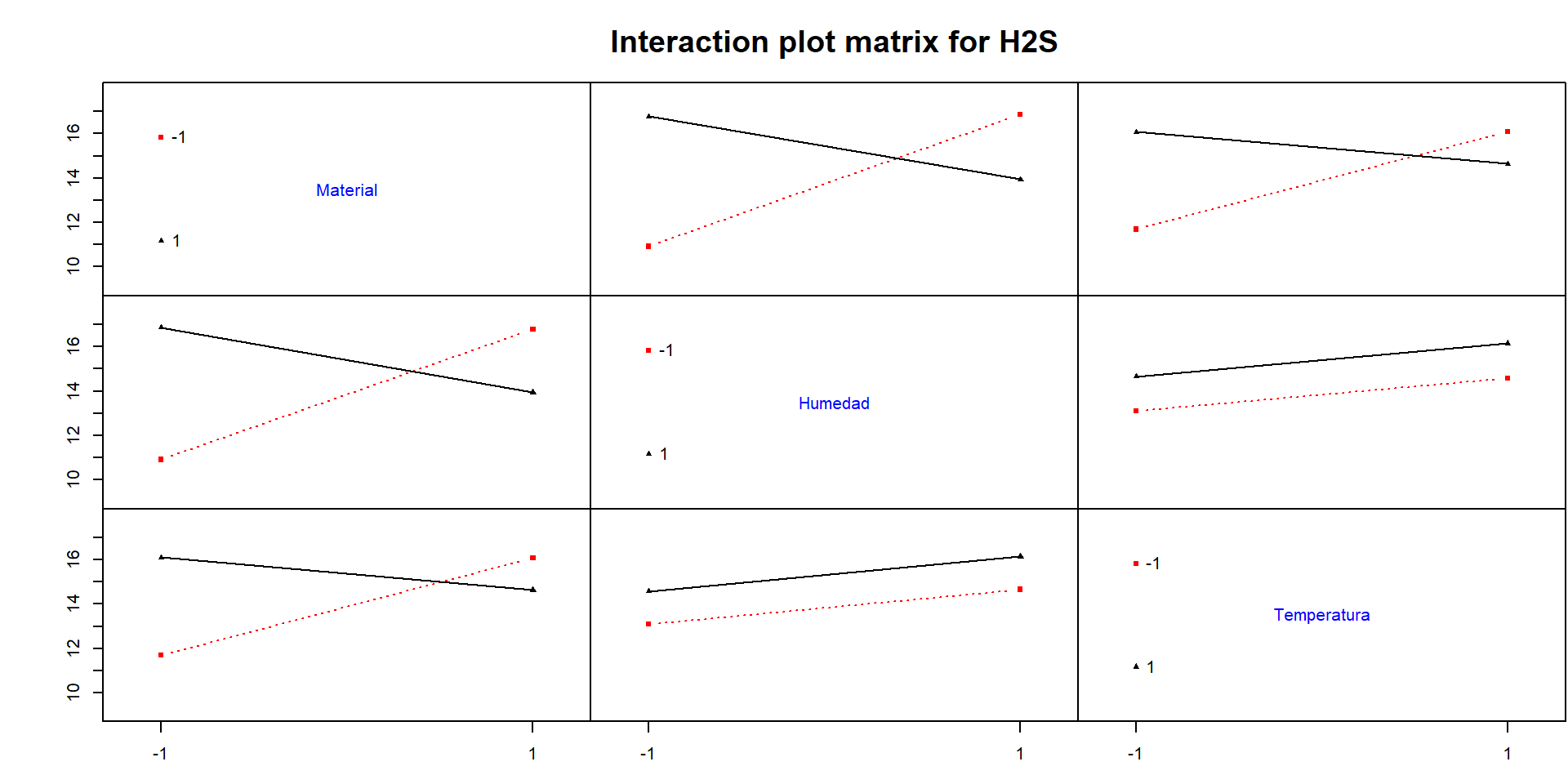
Interacciónes
Code
# Cargar la librería DoE.baselibrary(DoE.base)# Utilizando IAPlot para interacciones IA <-IAPlot(fit, response ="H2S", interaction =c("Material", "Humedad", "Temperatura"))
 -
-